From Relevance to Authority: Authority-aware Generative Retrieval in Web Search Engines¶
研究动机与背景¶
生成式信息检索(Generative Information Retrieval, GenIR)将检索任务重新定义为文本生成问题,模型直接生成文档标识符(DocID)来满足用户查询需求。近年来 GenIR 在学术研究和工业应用中取得了显著进展,已被应用于电商搜索、外卖配送、金融服务等场景。然而,现有 GenIR 方法主要优化语义相关性,忽略了文档权威性(document authority)这一关键维度。
在医疗健康、金融等高风险领域,仅依赖语义相关性进行检索存在严重隐患。如图 1 所示,对于"糖尿病早期症状"这样的查询,纯相关性模型可能将一个未经验证的个人健康博客(Doc 1)与官方医学协会网站(Doc 2)给出相近的排名分数,因为两者在话题上都高度相关。但前者的内容可能包含不准确或未经验证的信息,后者才是可信赖的权威来源。
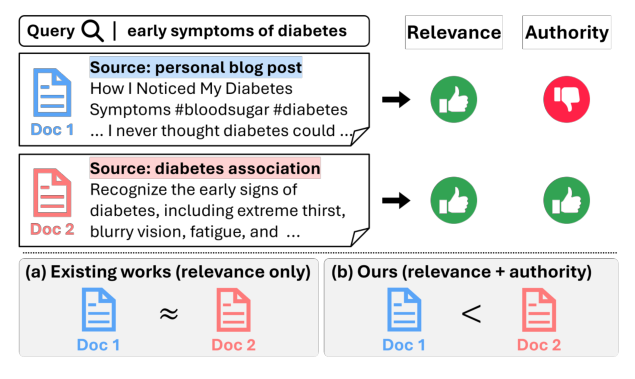
将文档权威性整合到 GenIR 面临三大挑战:(i)定义权威性:仅靠文本线索难以区分精心伪装的推广内容和真正权威的来源,难以在大规模下量化权威性;(ii)学习权威性:在不损害语义相关性的前提下,将权威性这一微妙且复杂的概念注入模型是非平凡的,需要超越标准微调的训练方法;(iii)部署权威性感知模型:直接替换现有生产检索器不切实际且有风险,模型必须能无缝集成到大规模搜索平台的现有流水线中。
核心方法:AuthGR 框架¶
本文提出 Authority-aware Generative Retriever(AuthGR),首个将文档权威性系统性整合到 GenIR 中的框架。如图 2 所示,AuthGR 包含三个核心组件:(i)Multimodal Authority Scoring,利用视觉语言模型(VLM)从文本和视觉线索中量化文档可信度;(ii)Three-Stage Training Pipeline,通过领域持续预训练(CPT)、监督微调(SFT)和群体相对策略优化(GRPO)逐步注入权威性意识;(iii)Hybrid Ensemble Pipeline,将 AuthGR 与现有检索器集成以实现稳健部署。
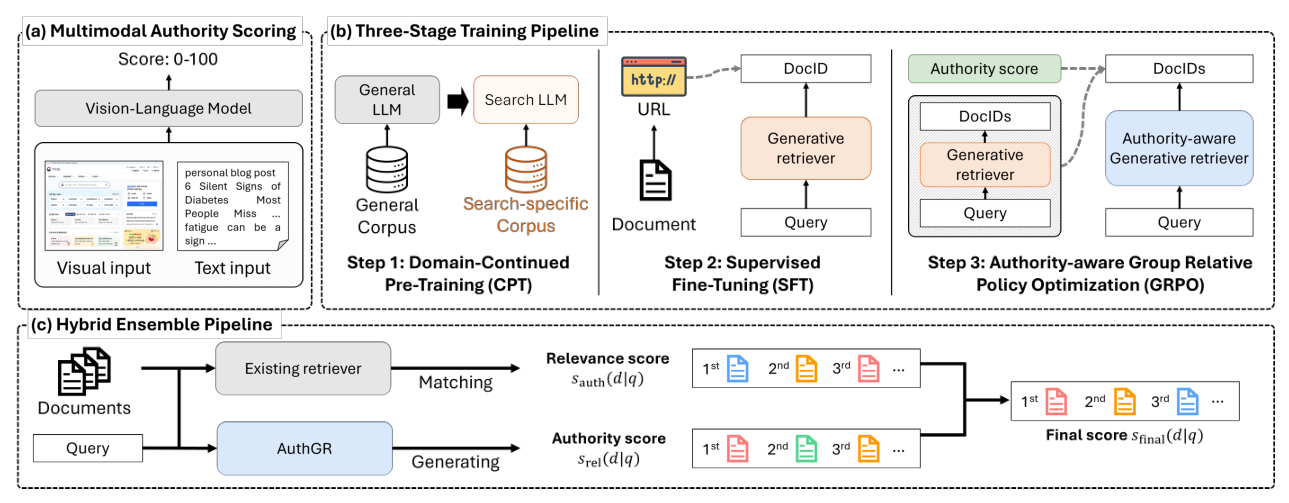
3.1 Multimodal Authority Scoring¶
为了在大规模下量化文档权威性,本文提出了 Multimodal Authority Scoring,自动化模拟人类评估者的判断过程。传统系统依赖 PageRank 等链接结构等碎片化信号,难以全面捕捉可信度。相比之下,人类评估者能综合文本内容、视觉设计和广告模式等多方面线索进行判断。
为复刻这一直觉,本文使用视觉语言模型(VLM)作为人类评估者的可扩展代理。具体而言,VLM 同时处理两类信号:
- 文本信号:包括文档标题、正文内容和 URL 元数据
- 视觉信号:来自页面级截图
视觉信号的整合至关重要,因为推广内容常模仿权威语言风格,仅靠文本难以识别欺骗性内容。视觉线索(如广告侵入程度、版面布局质量)对于区分真正权威性和精巧伪装至关重要。
VLM 采用综合评估 rubric,从 Expertise(专业性)、Officialness(官方性) 和 Public Interest(公共利益) 三个核心维度进行评估,并辅以对商业意图和有害内容的检查。文档 $d$ 的权威性分数定义为:
$$\text{Authority}(d) = f_{\text{VLM}}(T(d), V(d)) \in [0, 100] \tag{1}$$
其中 $f_{\text{VLM}}$ 是 VLM 的评分函数,$T(d)$ 和 $V(d)$ 分别表示文本和视觉特征。模型输出一个分数和简洁的自然语言解释。该分数随后在 GRPO 阶段作为奖励信号,显式引导模型优先选择高权威文档。
VLM 评分与人类判断的一致性验证:通过与人类二分类专业性标签的比较(Table 6),VLM 分数展现出强相关性——Point-biserial 相关系数 $r = 0.495$($p < 0.001$),ROC-AUC 为 0.915,Matthews 相关系数为 0.526。在多模态设置下(文本+图片),VLM 在 40,000 个网站上达到 97% 的准确率,显著优于纯文本(81%)和纯图片(92%)设置。
评分效率与可扩展性:采用三种优化策略——批量请求、多样本请求(将多个站点合并到单个 prompt)、结构化 JSON 输出格式。生产环境中每季度对全库重新评分一次,约 10 万个站点需 3000 万 tokens。增量更新通过梯度提升回归树模型监控内容变化,仅对分数偏差显著的站点触发重新评分。
3.2 Three-Stage Training Pipeline¶
AuthGR 通过三个阶段逐步将权威性嵌入检索器。生成目标采用host-level URL 作为文档标识符(如使用 "plus.gov.kr" 而非完整 URL),host 级别粒度降低噪声并暴露来源身份,为权威性建模提供稳定基础。
3.2.1 Domain-Continued Pre-Training(CPT)¶
第一阶段通过领域持续预训练将通用 LLM 适配到搜索领域,弥合通用语言知识和结构化 query-document 关联之间的差距。具体地,利用大规模搜索日志,格式化为 [Query + URL + Title + Body] 的拼接序列。这种结构使模型能内化内容与来源身份之间的关联——例如学习到 ".gov" 域名与官方机构相关。模型参数 $\theta$ 通过标准语言建模目标更新:
$$\mathcal{L}_{\text{CPT}} = -\sum_t \log p_\theta(x_t \mid x_{<t}) \tag{2}$$
其中 $x_t$ 表示拼接序列中的第 $t$ 个 token。通过将 URL 视为有意义的语义单元而非随机字符串,CPT 为后续的监督映射和权威性对齐建立了稳健的先验。
3.2.2 Supervised Fine-Tuning(SFT)¶
SFT 阶段优化模型在给定查询下生成相关 DocID 的能力,将 CPT 中隐含的 query-URL 关联转化为稳健的排序能力。损失函数为 ground truth DocID 序列的负对数似然:
$$\mathcal{L}_{\text{SFT}} = -\mathbb{E}_{(q,d) \sim \mathcal{D}} \left[ \log P_\theta(d \mid q) \right] \tag{3}$$
其中 $P_\theta(d \mid q) = \prod_{t=1}^{L} p_\theta(y_t \mid q, y_{<t})$ 表示生成 DocID 序列 $y = (y_1, \ldots, y_L)$ 的概率。
训练数据来自大规模商业搜索引擎的真实点击日志。由于点击日志固有的位置偏差和误点击噪声,本文采用混合过滤策略:(i)基于频率的剪枝,移除不稳定的长尾查询;(ii)使用辅助排序器进行相关性验证,丢弃语义不匹配的对。实验显示,过滤掉 63% 的原始数据后,在策划子集上训练使 P@3 提升 16.62%,收敛速度加快 40%。
3.2.3 Authority-Aware Ranking with GRPO¶
最终阶段采用偏好优化将模型与权威性信号对齐。SFT 平等对待所有有效文档,无法捕捉可信度的内在差异。简单的替代方案如加权交叉熵(WCE)是逐点(pointwise)的,缺乏有效排序所需的探索机制。
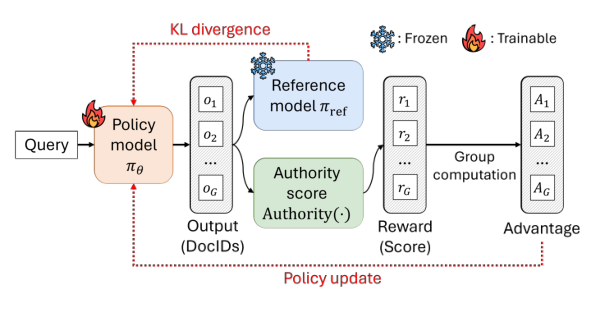
如图 3 所示,对于给定查询 $q$,从当前策略 $\pi_{\theta_{\text{old}}}$ 采样 $G$ 个候选 DocID $O = \{o_1, \ldots, o_G\}$,每个输出 $o_i$ 获得标量奖励 $r_i = \text{Authority}(d_i)$。然后计算优势值 $A_i = \frac{r_i - \text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})}$,通过组内奖励归一化。策略通过以下目标优化:
$$\mathcal{L}_{\text{GRPO}} = \mathbb{E}\left[q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(O|q)\right]$$
$$\frac{1}{G}\sum_{i=1}^{G}\left[\min(\rho_i A_i, \text{clip}(\rho_i, 1-\epsilon, 1+\epsilon)A_i) - \beta \, D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})\right] \tag{4}$$
其中 $\rho_i = \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}$ 是似然比,$\pi_\theta$ 和 $\pi_{\text{ref}}$ 分别是当前策略和参考模型(用 SFT 模型初始化)。超参数 $\beta$ 和 $\epsilon$ 分别调节 KL 惩罚和裁剪范围。该阶段使模型能在简单相关性之外区分权威性水平,通过有效平衡探索与利用来实现。
为保证训练稳定性,GRPO 使用严格过滤的高频查询数据集,聚焦于八个高风险领域(健康、教育、信息技术、金融、育儿、社会、动物、招聘),并使用预计算的权威性分数作为奖励。
3.3 Hybrid Ensemble Pipeline for Deployment¶
生产环境中,AuthGR 通过 Hybrid Ensemble Pipeline 与现有检索器协同工作。现有检索器提供相关性分数 $S_{\text{rel}}(d \mid q)$ 以覆盖广泛的文档集合,AuthGR 生成一组与权威性对齐的 DocID 集合 $\mathcal{D}_{\text{auth}}(q)$。对于 $d \in \mathcal{D}_{\text{auth}}(q)$,通过线性衰减得到归一化分数:
$$S_{\text{auth}}(d \mid q) = \frac{N - \text{rank}(d) + 1}{N} \tag{5}$$
其中 $N$ 是生成的 DocID 数量。最终分数计算为:
$$S_{\text{final}}(d \mid q) = S_{\text{rel}}(d \mid q) + \lambda \cdot S_{\text{auth}}(d \mid q) \cdot \mathbb{I}[d \in \mathcal{D}_{\text{auth}}(q)] \tag{6}$$
其中 $\mathbb{I}[\cdot]$ 是指示函数,$\lambda$ 控制权威性信号的强度。该公式保留了现有排序器的召回能力,同时注入 AuthGR 的权威性知识,产出既语义相关又可信的结果。
实验设置¶
数据集¶
数据来自韩国大型商业搜索引擎的日志,三个阶段分别使用不同规模的数据:
| 阶段 | 数据量 | 说明 |
|---|---|---|
| CPT | 985 万对 | [Query; URL; Title; Body] 格式的网页爬取数据 |
| SFT | 395 万对 | 高风险领域(健康/金融),周查询量 QC > 50,过滤 63% 噪声 |
| GRPO | 1.38 万查询 | QC > 200,375 万 host URL 预计算权威性分数 |
CPT 阶段额外设计了 [Query; Title] 和 [Query; Snippet] 等多样化序列格式,使模型学习 URL 与内容的结构关系和可靠性。
Baselines¶
考虑到目标语言为韩语,采用两类 baselines:
In-context Learning(ICL):Gemma 3(27B)、EXAONE 3.5(32B)、K-EXAONE(236B)、Qwen3(32B)、LLaMA 3.1(405B)、LLaMA 4 Scout(109B)、LLaMA 4 Maverick(400B)、DeepSeek-R1(671B)、DeepSeek-V3(671B)、DeepSeek-V3.2(685B)、GPT-4o
Supervised Fine-tuning(SFT):HyperCLOVAX(0.5B/1.5B)、LLaMA 3.2(1B/3B)、T5Gemma 2(0.5B/2B)、Qwen3(1.7B/4B)、HyperCLOVAX(14B)
实现细节¶
- 基础模型:3B decoder-only transformer,初始化自 HyperCLOVAX-SEED-Vision-Instruct 的语言组件
- GRPO rollout group size $G = 256$,KL 系数 $\beta = 0.2$
- 推理使用 beam search,beam size 为 10
- Ensemble 系数 $\lambda = 0.6$(通过验证集调优)
- 训练框架:PyTorch + DeepSpeed ZeRO-3,8×A100 GPU
- 优化器:AdamW($\beta_1 = 0.9$,$\beta_2 = 0.95$,weight decay = 0.01)
- 学习率调度:cosine scheduler,warmup ratio 0.03
- 最大输入长度:2,048 tokens
- CPT:全局 batch size 256,peak learning rate $5.0 \times 10^{-6}$
- SFT:3 个 epoch,全局 batch size 512,learning rate $1 \times 10^{-6}$
- GRPO:1 个 epoch,温度 1.5,top-$p$ 为 0.8,top-$k$ 为 50
- WCE baseline:$\alpha = 4.0$
- 推理最大生成长度:50 tokens(足以覆盖 host-level URL)
- 每个 DocID 最大生成长度 50 tokens
评估协议¶
三种评估方式:
- Offline Evaluation:3,000 个专家查询,人工标注 ground truth,评估 Precision@3 和 Recall@{5,10}
- Human Evaluation:500 个查询的盲测 side-by-side 比较,5 分制量表同时衡量相关性和权威性
- Online A/B Test:在大规模搜索平台上分析数百万次交互的用户参与指标
主要实验结果¶
Offline Evaluation¶
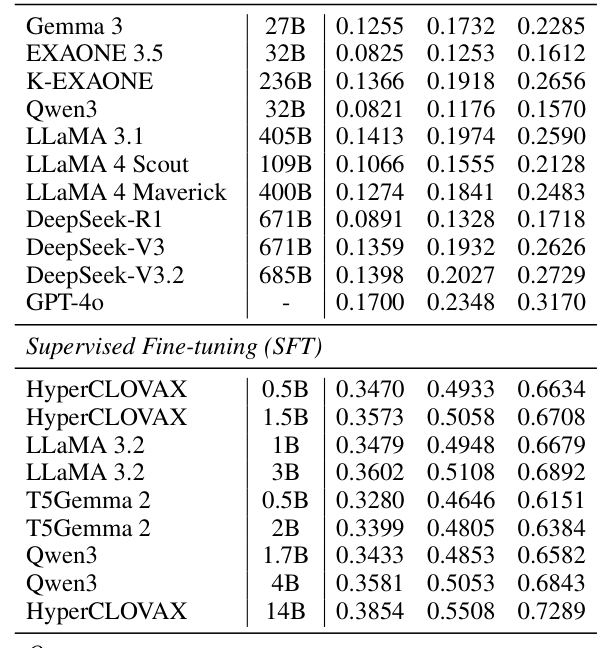
| Model | Size | P@3 | R@5 | R@10 |
|---|---|---|---|---|
| In-context Learning (ICL) | ||||
| Gemma 3 | 27B | 0.1255 | 0.1732 | 0.2285 |
| EXAONE 3.5 | 32B | 0.0825 | 0.1253 | 0.1612 |
| K-EXAONE | 236B | 0.1366 | 0.1918 | 0.2656 |
| Qwen3 | 32B | 0.0821 | 0.1176 | 0.1570 |
| LLaMA 3.1 | 405B | 0.1413 | 0.1974 | 0.2590 |
| LLaMA 4 Scout | 109B | 0.1066 | 0.1555 | 0.2128 |
| LLaMA 4 Maverick | 400B | 0.1274 | 0.1841 | 0.2483 |
| DeepSeek-R1 | 671B | 0.0891 | 0.1328 | 0.1718 |
| DeepSeek-V3 | 671B | 0.1359 | 0.1932 | 0.2626 |
| DeepSeek-V3.2 | 685B | 0.1398 | 0.2027 | 0.2729 |
| GPT-4o | - | 0.1700 | 0.2348 | 0.3170 |
| Supervised Fine-tuning (SFT) | ||||
| HyperCLOVAX | 0.5B | 0.3470 | 0.4933 | 0.6634 |
| HyperCLOVAX | 1.5B | 0.3573 | 0.5058 | 0.6708 |
| LLaMA 3.2 | 1B | 0.3479 | 0.4948 | 0.6679 |
| LLaMA 3.2 | 3B | 0.3602 | 0.5108 | 0.6892 |
| T5Gemma 2 | 0.5B | 0.3280 | 0.4646 | 0.6151 |
| T5Gemma 2 | 2B | 0.3399 | 0.4805 | 0.6384 |
| Qwen3 | 1.7B | 0.3433 | 0.4853 | 0.6582 |
| Qwen3 | 4B | 0.3581 | 0.5053 | 0.6843 |
| HyperCLOVAX | 14B | 0.3854 | 0.5508 | 0.7289 |
| Ours | ||||
| AuthGR (SFT) | 3B | 0.3555 | 0.5058 | 0.6899 |
| AuthGR (CPT+SFT) | 3B | 0.3725 | 0.5293 | 0.7031 |
| AuthGR (Full) | 3B | 0.3856 | 0.5464 | 0.7175 |
关键发现:
- AuthGR (Full) 的 3B 模型在所有 baselines 中取得最高 P@3,与 14B 的 HyperCLOVAX 性能持平,尽管参数量小 4.7 倍
- 三阶段训练的有效性得到验证:CPT 确保领域适配,GRPO 显式优化权威性
- ICL baselines 表现有限,即使是 685B 的 DeepSeek-V3.2 的 P@3 也仅为 0.1398,凸显了 task-specific fine-tuning 对生成式检索的必要性
- GPT-4o 在 ICL 中表现最好(P@3=0.17),但仍远低于 SFT 方法
Human Evaluation¶
| Production | Hybrid Ensemble | |
|---|---|---|
| Label score | 3.06 | 3.41 |
在 500 个查询的盲测 side-by-side 比较中,AuthGR 增强的 Hybrid Ensemble 在 1-5 分制下获得 3.41 的平均分,相比生产系统的 3.06 提升了 11.4%。这证实显式优化权威性能让用户感知到更相关和可信的结果。
Online A/B Test¶
| Metrics | Control | Treatment |
|---|---|---|
| Pages with clicks | +0.08% | +21.36% |
| Total document clicks | +0.22% | +22.07% |
| Top 1 document CTR | +0.87% | +22.83% |
| Top 3 document CTR | +0.81% | +22.68% |
| Top 5 document CTR | +0.81% | +22.76% |
在商业搜索平台上进行的大规模 A/B 测试(2025 年中,持续数天,数百万次交互)展现了显著改善:
- "Pages with clicks" 增长 21.36%
- "Total document clicks" 增长 22.07%
- Top-1 document CTR 提升 22.83%
这些结果表明,权威性感知排序显著提升了头部结果的质量和用户参与度。
消融与分析¶
训练阶段消融¶
| Model | SFT | CPT | GRPO | P@3 | R@5 | R@10 |
|---|---|---|---|---|---|---|
| AuthGR (0.5B) | ✓ | 0.3470 | 0.4933 | 0.6634 | ||
| ✓ | ✓ | 0.3515 | 0.4989 | 0.6651 | ||
| AuthGR (3B) | ✓ | 0.3555 | 0.5058 | 0.6899 | ||
| ✓ | ✓ | 0.3660 | 0.5216 | 0.6986 | ||
| ✓ | ✓ | 0.3725 | 0.5293 | 0.7031 | ||
| ✓ | ✓ | ✓ | 0.3856 | 0.5464 | 0.7175 |
四个关键发现:
- 完整流水线最优:Full pipeline 相比 SFT baseline 在 P@3 上提升 8.5%
- CPT 贡献最大:CPT 带来 4.8% 的 P@3 提升,为后续 GRPO 建立领域基础
- GRPO 收益随模型规模增长:3B 模型获得 3.1% 增益 vs 0.5B 的 1.3%,暗示更大模型能更好地内化权威性概念
- 阶段间存在协同效应:CPT 之后应用 GRPO 获得 3.5% 增益,高于仅 SFT 后的 3.0%
排序优化方法对比¶
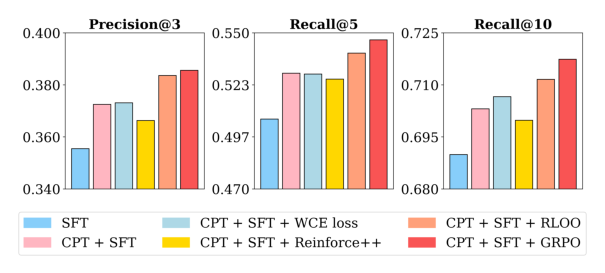
对比了四种排序优化方法在 CPT+SFT 基线之上的表现:
- GRPO:P@3 增益最高,达 3.5%
- RLOO:P@3 增益 3.0%
- WCE:仅 0.2% 的边际增益
- Reinforce++:反而降低 1.7%
组级方法(GRPO、RLOO)显著优于逐点方法(WCE、Reinforce++),证实建模候选项间的相对顺序比逐点优化更适合排序任务。
权威性分数分布变化¶
| Training stage | Mean(↑) | Median(↑) | Low(↓) | High(↑) |
|---|---|---|---|---|
| CPT+SFT | 87.2 | 90.0 | 118 | 2,754 |
| + GRPO (Binary) | 88.0 | 90.0 | 115 | 2,804 |
| + GRPO (Linear) | 90.4 | 95.0 | 106 | 2,877 |
GRPO 成功重塑了生成文档的权威性分布。均值从 87.2 提升至 90.4,中位数达到 95.0。低权威性生成(0-60 分)减少 10.2%,高权威性生成(90-100 分)增加 4.5%,证实模型系统性地学会了优先选择可信来源。
奖励缩放策略对比¶
| Scaling strategies | P@3 | R@5 | R@10 |
|---|---|---|---|
| Binary | 0.3820 | 0.5375 | 0.7133 |
| Binning | 0.3841 | 0.5420 | 0.7151 |
| Sigmoid | 0.3833 | 0.5377 | 0.7147 |
| Linear (AuthGR) | 0.3856 | 0.5464 | 0.7175 |
在 GRPO 中评估了四种奖励缩放策略:Binary(固定阈值二分)、Binning(五级离散化)、Sigmoid(非线性变换)、Linear(直接使用原始分数)。Linear 策略在所有指标上一致最优,表明保留细粒度权威性差异比粗粒度近似更有效。
超参数敏感性¶
- KL 惩罚系数 $\beta$:最优范围 0.1-0.2。将 $\beta$ 从 0.01 设为 0.2 时,Precision@3 和 Recall@5 分别提升 10.6% 和 9.7%。显式约束训练策略与参考策略之间的 KL 散度对于保留 SFT 阶段习得的相关性生成能力至关重要
- Rollout group size $G$:最佳范围 128-512。过少的 rollout 无法提供足够信息计算组内相对优势
数据过滤效果¶
| Data filtering | P@3 | R@5 | R@10 |
|---|---|---|---|
| w/o filtering | 0.3194 | 0.4642 | 0.6299 |
| w/ filtering | 0.3725 | 0.5293 | 0.7031 |
| Gain (%) | 16.62 | 14.02 | 11.62 |
过滤掉约 63% 的原始数据(从近 1100 万减至约 400 万),所有指标显著提升。Precision@3 提升 16.6%,证明在生成式检索中数据质量远比数量重要。过滤阈值 2.1 为最优点,超过此值则因训练信号不足导致性能下降。
推理效率¶
| Model | Size | Latency (ms) | Throughput |
|---|---|---|---|
| HyperCLOVAX (SFT) | 14B | 2,881 | 1.30 |
| AuthGR (Ours) | 3B | 1,225 | 3.26 |
在 NVIDIA A100 上,AuthGR 3B 相比 HyperCLOVAX-14B (SFT) 延迟降低 2.35 倍,吞吐量提升 2.51 倍,同时保持可比的排序性能。
训练效率¶
在 8×A100 GPU 上,完整三阶段训练约 83 小时:
- CPT:57 小时(985 万样本)
- SFT:20 小时(395 万样本)
- GRPO:6 小时(1.38 万样本)
GRPO 阶段的开销极小,特别适合频繁的权威性对齐更新。
统计显著性¶
| Metric | Gain | p-value | 95% CI |
|---|---|---|---|
| P@3 | 2.31% | 0.0277 | [0.0012, 0.0158] |
| R@5 | 1.65% | 0.0483 | [-0.0002, 0.0170] |
AuthGR 3B 在 P@3 和 R@5 上均统计显著优于 14B baseline($p < 0.05$,paired t-test with 5,000 bootstrap resampling)。
每个训练阶段的增益也均统计显著($p < 0.0001$),完整流水线相比 SFT 带来 +7.51% 的 P@3 提升。
讨论与局限性¶
核心贡献¶
AuthGR 是首个将文档权威性系统性整合到生成式检索中的框架,解决了现有 GenIR 方法忽视内容可信度的关键缺陷。三个设计值得借鉴:
- Multimodal Authority Scoring:利用 VLM 综合文本和视觉线索量化权威性,是传统 PageRank 类方法的现代化替代,97% 准确率证明了多模态信号的互补价值
- 渐进式训练策略:CPT→SFT→GRPO 的三阶段设计优雅地分离了领域适配、任务学习和偏好对齐三个目标,阶段间的协同效应(CPT 后 GRPO 增益更大)验证了这种分阶段设计的必要性
- Hybrid Ensemble 部署:通过可调参数 $\lambda$ 平衡相关性和权威性,避免了直接替换生产系统的风险,是值得参考的工业部署模式
局限性¶
- 奖励信号单一:主要依赖 VLM 权威性分数作为 GRPO 奖励。更多样化的奖励信号(如用户停留时间、滚动深度等隐式反馈)可能进一步提升效果
- 规模瓶颈:验证了 3B 显著优于 0.5B,但未探索超过 3B 的规模。作者指出可通过量化、投机解码等推理优化技术解锁更大模型的权威性推理潜力
- 语言和平台特异性:实验均在韩语搜索引擎上进行,框架的跨语言和跨平台泛化性尚未验证
- WCE 作为 pointwise baseline 的局限:论文指出 WCE 缺乏探索能力,但 WCE 的 $\alpha$ 值(4.0)可能未充分调优
工业部署价值¶
AuthGR 已成功部署到 Naver 商业搜索引擎,A/B 测试中所有用户参与指标均获得 20%+ 的提升。3B 模型即可匹配 14B 性能,延迟降低 2.35 倍,吞吐量提升 2.51 倍,对于大规模搜索服务的成本控制具有重要参考价值。权威性评分的增量更新策略(梯度提升回归树 + 季度全量重评)也为工业规模的内容质量管理提供了实用方案。