Foundation Models to Unlock Real-World Evidence from Nationwide Medical Claims¶
研究动机与背景¶
真实世界数据(Real-World Data, RWD)已成为补充随机对照试验的关键证据来源,覆盖监管评估、临床决策与卫生政策制定等场景。RWD 的两大主源——电子健康档案(EHR)和管理性医保理赔(administrative claims)——结构互补:
- EHR:含丰富临床信息(化验、影像、临床叙事),但常因患者跨多个医疗系统就诊而不完整;缺乏明确观察窗,"未记录" 与 "未发生" 难以区分,引入假阴性偏差。
- Claims(理赔):缺细粒度临床细节,但能在大规模人群与给付方系统内提供完整、标准化、纵向的 utilization / expenditure 记录;以 enrollment 期限为锚定,观察窗清晰。
围绕 RWD 的 healthcare foundation model 研究路线已初具规模:
- 早期 EHR 上的 BERT 风格模型:BEHRT(2020)、Med-BERT(2021)证明了将临床事件序列化用 Transformer 预训练能改善疾病预测。
- 生成式 EHR 模型:Foresight(Lancet Digital Health, 2024)、ETHOS(npj Digital Medicine, 2024)、Motor(2023)、CEHR-GPT(2024)将 EHR 序列建模扩展到时间到事件预测、零/少样本适配。
- 大规模疾病通用模型:Delphi(Nature 2025, [16])训练单个 transformer 同时预测 1000+ 种疾病的发生时间,性能逼近单病专门模型;Curiosity(arXiv 2508.12104, [17])展示 EHR 上的可扩展性能随数据/模型规模单调改善。
但论文指出现有工作有 四点局限:
- 数据规模和覆盖有限:多数模型基于单一医院系统或中等规模队列,无法捕获大规模异质轨迹。
- EHR-centric:模型主要在 EHR 上开发,claims-based 建模和跨数据源验证仍稀少。
- 任务范围窄:评估集中在疾病预测 benchmark,缺乏更广义的 healthcare dynamics(财务、医疗资源、因果推断)。
- post-training 探索不足:缺少专门的任务适配阶段,限制了模型在复杂下游任务上的泛化能力。
为此本文提出 ReClaim:基于 Merative MarketScan 全美理赔数据库(2008-2022,43.8B 事件,118M+ 入组人)从零训练的 decoder-only transformer 基础模型,规模扩到 1.7B 参数,并通过任务专属 post-training 适配 disease onset prediction。三个下游任务:(1) 1208 种 ICD-10 疾病发生预测;(2) 下年度医疗支出预测;(3) RWE(real-world evidence)因果推断中的倾向得分建模。
核心方法/模型架构¶
ReClaim 总体设计¶
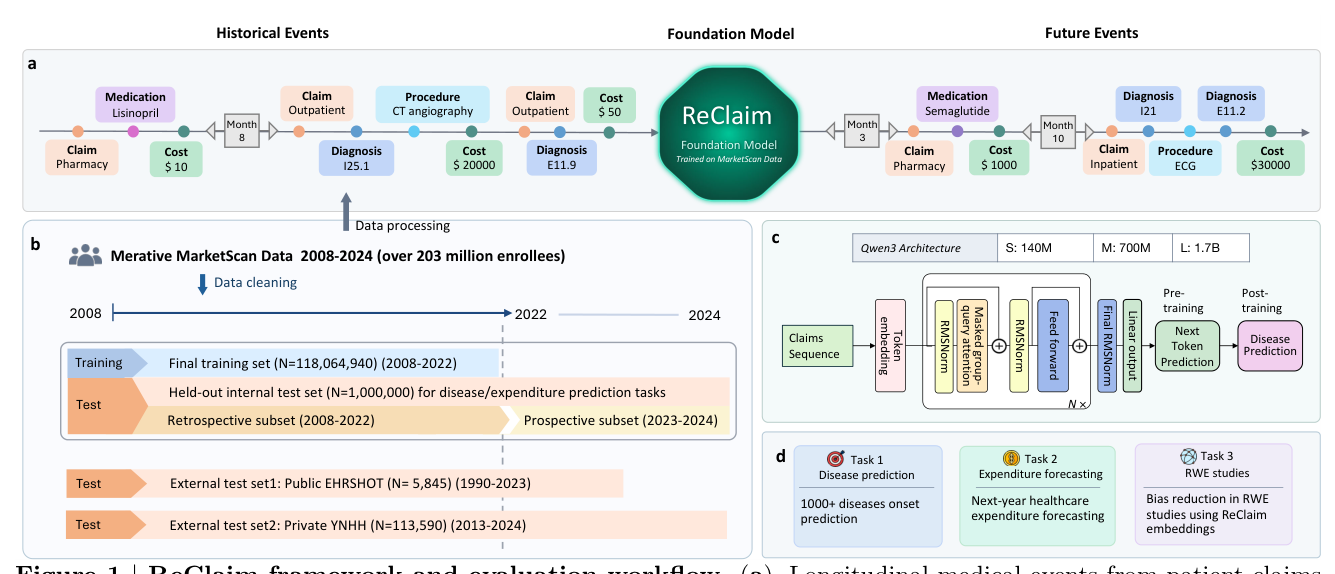
ReClaim 把每位入组人的纵向理赔记录转换为按时间排序的 token 序列,序列联合编码:
- enrollment 历史(开始/结束、保险类型、地理位置)
- 临床事件(diagnoses、procedures、medications)
- 健康支出(gross payment)
- 时间锚点(出生年、年龄、月份间隔、新年标记)
模型采用 Qwen3 dense decoder-only 架构家族([32]),但所有权重 从零训练(不复用任何 Qwen3 checkpoint)。提供三个规模:
| 规模 | hidden size | layers | attn heads | KV heads | FFN dim | 词表 | max pos |
|---|---|---|---|---|---|---|---|
| ReClaim-S | 140M / 1024 | 8 | 16 | 8 | 2048 | 20865 | 4096 |
| ReClaim-M | 700M / 2048 | 16 | 24 | 12 | 4096 | 20865 | 4096 |
| ReClaim-L | 1.7B / 2048 | 32 | 32 | 16 | 4096 | 20865 | 4096 |
三档共享相同分词器和词表,性能差异主要来自模型容量(depth × width)。
训练目标 1:大规模 next-token 预训练¶
给定 token 序列 $x_{1:T}$,最大化对数似然:
$$\sum_{t=1}^{T} \log p_\theta(x_t \mid x_{<t}) \tag{1}$$
实现为带因果 mask 的交叉熵。除标准 CE 外,还添加 z-loss 正则项 抑制 logit 漂移:
$$Z_t = \sum_{v \in \mathcal{V}} \exp(s_{t,v}) \tag{2}$$
$$\mathcal{L}_z = \lambda \cdot \mathbb{E}\bigl[(\log Z_t)^2\bigr], \quad \lambda = 10^{-4} \tag{3}$$
总预训练损失:
$$\mathcal{L} = \mathcal{L}_\text{CE} + \mathcal{L}_z \tag{4}$$
z-loss 通过惩罚 log-partition 的平方期望,限制 logit 量级和全局漂移,显著改善大规模训练稳定性——减少 loss 尖峰、缩小 logit scale 振荡。
训练目标 2:disease-onset post-training¶
由于预训练优化的是通用序列建模而非 endpoint-specific 风险预测,作者增加 task-specific post-training 阶段。从预训练数据中随机抽样 100K 入组人(要求 ≥2 个月历史),将每条序列改写为 prompt-response 对:
- 在序列中随机插入
<INSTRUCT-DX>instruct token(约束此前至少 2 个月历史); - instruct token 之前的所有 token 作为 prompt;
- instruct token 之后仅保留新发疾病的 diagnosis token(其他无关 token 被剔除),作为 response。
监督只施加在 response 区域:
$$\sum_{k=1}^{K} \log p_\theta(y_k \mid p, y_{<k}) \tag{5}$$
这种"prompt 段不计 loss、response 段计 loss" 的设计避免预训练词表 / 分词器变化,把模型对齐到"从历史预测下一年新发疾病"的目标。推理时,只需在历史末尾追加 <NY> <INSTRUCT-DX> prompt,最后位置 logit 中疾病 token $k$ 的值即为该疾病的风险得分——避免 Monte Carlo 抽样多条完整序列的高昂代价(这是 Delphi 等先前生成式工作的标准做法)。
关键技术细节:分词器与序列设计¶
ReClaim 的核心创新之一是面向理赔数据特性设计的 tokenizer。
词表与 token 类型¶
词表共 20,865 个 token,分两大类(详见 Table A8):
- Static 静态 token:与时间无关,定位独立于事件流。包括
<SEX-1>/<SEX-2>(生物性别)、<INSTRUCT-DX>(post-training 指令标记)。 - Temporal 时间 token:以月为粒度聚合,按时间戳排序。包括:
- Time anchor:
<DOBYR-1974>(出生年)、<AGE-44>(首次事件年龄)、<NY>(新年)、<ATT-N>(N 个月间隔,N ∈ 0..12)。 - Enrollment:
<ERLST-CCAE>/<PLANTYP-5>/<CAP-0>/<EGEOLOC-04>/<ERLED-...>编码计划类型、自付/包付状态、地理位置等。 - Clinical codes:
<DX-MAJOR_E11>(ICD-10 三位主码) /<DX-MINOR_9>(细分码),共 5474 个 DX;<PROC-...>(SNOMED CT / CPT-4)共 12,473 个;<RX-...>(RxNorm 成分)2473 个。 - Cost token:100 个
<COST-XX>表示费用(见下)。 - Encounter-specific:
<VT-outpatient>、<VT-pharmacy>、<VT-inpatient>、<DS-X>(出院状态)、<LS-1>(长住院 ≥7 天)。
时间分辨率:月聚合¶
理赔虽以"日"为粒度上传,但因报销延迟、批量上传,日级真实顺序失真。作者在 Day / Week / Month 三种聚合粒度做 ablation:
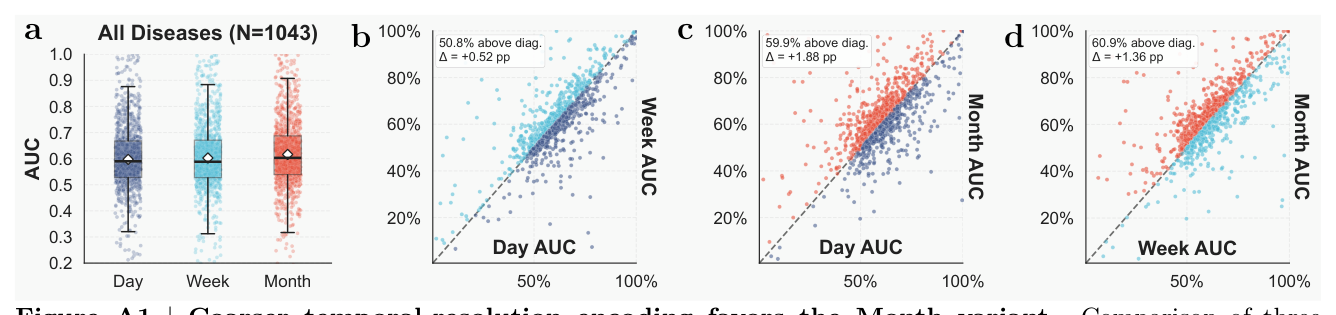
| 粒度 | mean AUC | 中位数 |
|---|---|---|
| Day | 59.73% | 58.99% |
| Week | 60.26% | 58.82% |
| Month | 61.61% | 60.30% |
Month 在 1043 个共有疾病上压倒 Day(59.9% endpoints)和 Week(60.9% endpoints),且生成最短序列、最低算力开销。结论:理赔数据的最佳粒度受数据噪声特性主导,比 EHR 更粗是合理选择。
临床代码标准化¶
朴素拼接 ICD-9-CM、ICD-10、NDC、CPT 会得到 180,000+ token——对自回归建模而言代价过高。作者通过两步压缩词表:
- 跨版本映射:ICD-9-CM → ICD-10-CM(CMS GEM);CPT-4 / ICD-9-Proc / ICD-10-PCS → SNOMED CT(OHDSI Athena v20250827);NDC → RxNorm 成分。
- 层级分解:ICD-10-CM 拆成
MAJOR(前 3 位,类目)、MINOR(细分)、SUFFIX(修饰),细到 DX-MAJOR_E11 + DX-MINOR_9 表达 "Type 2 diabetes mellitus, with unspecified complications"。同一编码可能出现一次 MAJOR + 0..2 次 MINOR,保证完整可追溯。
未匹配标准词表的代码记 NOMAP;多对多映射(如组合药物)用 <PROC-COMBSTART> / <PROC-COMBEND> 包裹原子分组。
费用 token:科学计数法离散化¶
费用跨 8+ 个数量级(pharmacy 几美元 → inpatient 几万美元)。作者将每个月内同 claim type 的 gross payment 求和,再四舍五入到一位有效数字,编码为两位"科学计数法风格":
例:$2,400 → $2 × 10^3$ → token
<COST-23>(首位 2 + 阶 3); $859 → $9 × 10^2$ → token<COST-92>; $0 / 负值 →<COST-0>。
得到 100 个 cost token 覆盖到 $9 × 10^9$,对低值高分辨率、高值粗分辨率(信息密度匹配)。这种 log-discretization 让模型直接以 token 形式 ingest 费用,并在 expenditure 预测时通过抽样还原数值。
同月多事件确定性排序¶
理赔在同一月内可能有多事件。Table A7 定义两级排序:
- 事件级:anchor → enrollment-start → outpatient → pharmacy → inpatient → enrollment-end
- 事件内:
<VT-...>→<DX-PRINCIPAL>→ DX-MAJOR / DX-MINOR →<DX-SECONDARY>→ secondary DX →<PROC-PRINCIPAL>→ primary procedures →<PROC-SECONDARY>→ secondary procedures →<DS-...>/<LS-...>→<COST-...>
这套规则确保同月数据有唯一可复现的 token 顺序,避免训练时同一病人因排序不同被当作多个样本。
数据规模¶
- 预训练语料:MarketScan 2008-2022,118,064,940 入组人;平均序列长 517 token、纵向跨度 45 个月(约 60.6B 训练 token,43.8B 临床事件)。
- post-training:100K 入组人 prompt-response 对。
- 三大评估队列:1M MarketScan 内部 hold-out(追溯 + 前瞻),EHRShot 5,845 人,Yale New Haven 113,590 人。
- 一个独立 1M RWE 队列:用于因果推断研究。
实验设置¶
三大下游任务¶
- Disease onset prediction:1,208 个 ICD-10-CM 疾病 endpoint。每个疾病构造 case-control 队列(按 age / sex 分层),prediction time = 案例首次出现 token 前 ∆ 天的最近事件位置;控制者匹配同一 age/sex 子群。在 ∆ ∈ {1, 6, 12, 60} 月四档评估,AUC 用 DeLong 方差。
- Healthcare expenditure forecasting:预测下一历年总 gross payment,三种设定——连续回归(R²、MAE)、三类分层($1500/$15000 阈值,44 / 91 percentile)、HNHC 二分类($30000,95.6 percentile)。推理时抽样 20 条未来轨迹平均 cost token 反解 dollar 值。
- RWE / propensity score 修正:在 1M RWE 队列内做 GLP-1 RA vs SGLT-2i vs DPP-4i 三药类的 target trial emulation;用 LASSO logistic 回归估倾向得分,对比"无 embedding / Delphi embedding / ReClaim-L embedding"的 1:1 匹配残余偏差。残差以 EASE(expected absolute systematic error)于负控结果(NCO,34 个 ICD-10 outcome 与治疗无因果关系)上度量。
Baseline¶
- LightGBM([23]):每病一个 GBDT,输入是观察窗口内 demographic + 词袋频次(DX/PROC/RX)。监督式 supervised baseline。
- Delphi(Nature 2025, [16]):基于 transformer 的全 1000+ 病生成模型,按其公开实现 + 默认设置在完整 MarketScan 上训练。
主要实验结果¶
5.1 Disease onset prediction:在 1208 病上压倒所有 baseline¶
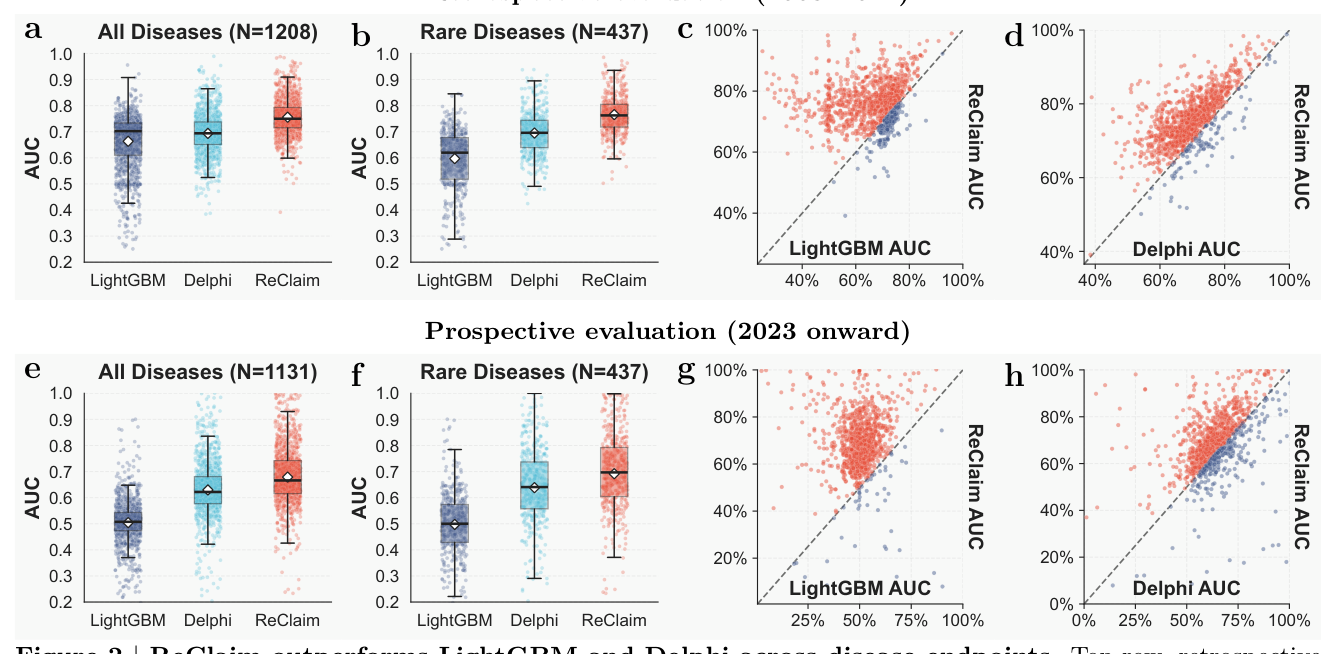
追溯评估(2008-2022 hold-out, N=1208 endpoints):
| 模型 | mean AUC | rare disease (N=437) | 显著性(Holm-adj 配对 Wilcoxon) |
|---|---|---|---|
| LightGBM | 66.34% | LightGBM 基线 | — |
| Delphi | 69.36% | +Δ 不详 | — |
| ReClaim-L | 75.57% | +16.87pp vs LightGBM, +7.07pp vs Delphi | $P_\text{Holm}=1.9 \times 10^{-70}$(vs LGB) / $1.4 \times 10^{-61}$(vs Delphi) |
按疾病配对:ReClaim 在 79.9% endpoints 击败 LightGBM(Δ +9.23pp,95% CI 8.56-9.91,$P=9.5 \times 10^{-126}$),在 92.0% endpoints 击败 Delphi(Δ +6.21pp,$P=1.1 \times 10^{-161}$)。
前瞻评估(2023+,N=1131):
| 模型 | mean AUC | rare disease |
|---|---|---|
| LightGBM | 50.44% | — |
| Delphi | 62.97% | — |
| ReClaim-L | 67.89% | +19.42pp vs LGB, +5.34pp vs Delphi |
时间漂移下 LightGBM 严重退化(66.34→50.44,跌 16pp)而 ReClaim 仅下降 7pp(75.57→67.89),说明序列预训练学到的是不依赖训练集时段的健康轨迹规律。
罕见病(prevalence < 5/10000):ReClaim 在 437 个罕见疾病上把 LightGBM 拉开 16.87pp / Delphi 7.07pp——这是论文最显著的卖点之一,因 LightGBM 在罕见病上明显退化(数据稀疏 + 词袋失真)。
5.2 外部验证:跨数据源迁移¶
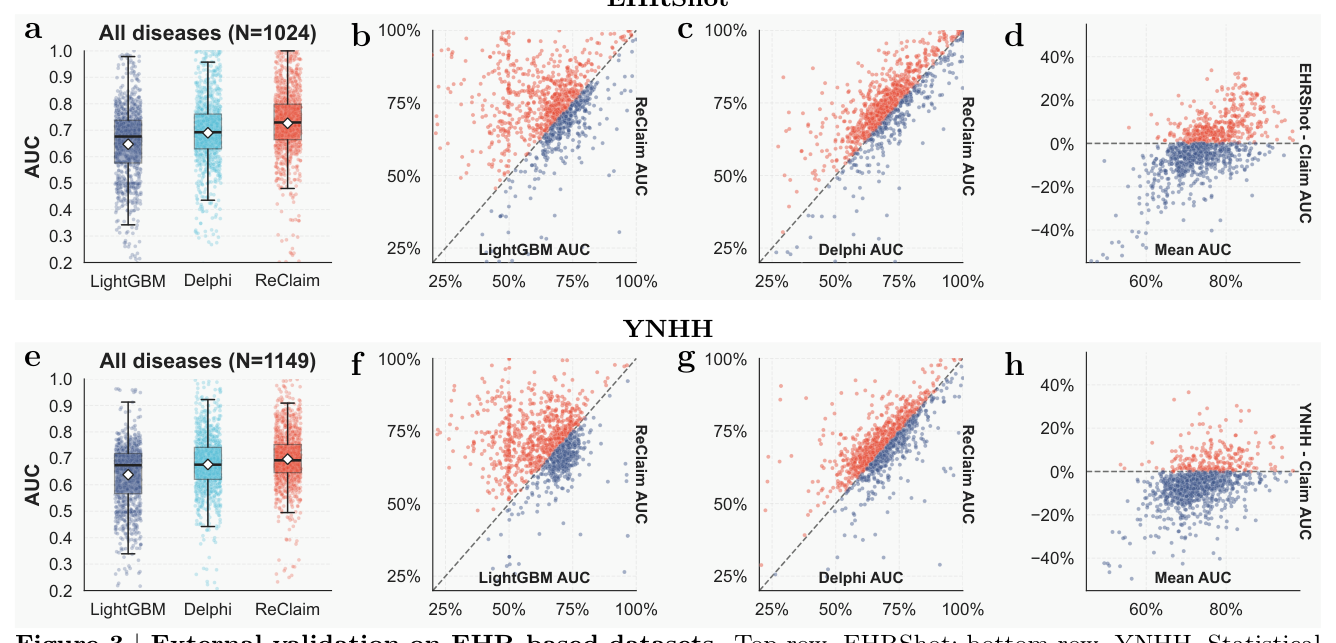
ReClaim 完全在 claims 上训练,但作者把 EHRShot(OMOP CDM 标准格式)和 YNHH 转换到与 MarketScan 相同的 trajectory schema(unmapped 字段填 MISSING,cost 全部 MISSING),评估迁移:
| 数据集 | LightGBM | Delphi | ReClaim-L |
|---|---|---|---|
| EHRShot (1024 共享病) | 64.72% | 69.03% | 72.64% |
| YNHH (1149 共享病) | 63.83% | 67.69% | 69.70% |
ReClaim 在 EHRShot 上击败 LGB 64.7% endpoints(Δ +7.92pp)、击败 Delphi 72.9% endpoints(Δ +3.61pp)。绝对性能比内域略低(EHRShot 平均 -2.78pp,YNHH -5.87pp),原因是 hospital-based 招募使疾病平均流行率比 MarketScan 高 2.95×(EHRShot)/ 1.49×(YNHH),加上 EHR 编码 / 时机不同。
5.3 跨临床域、人口学、预测期分层¶
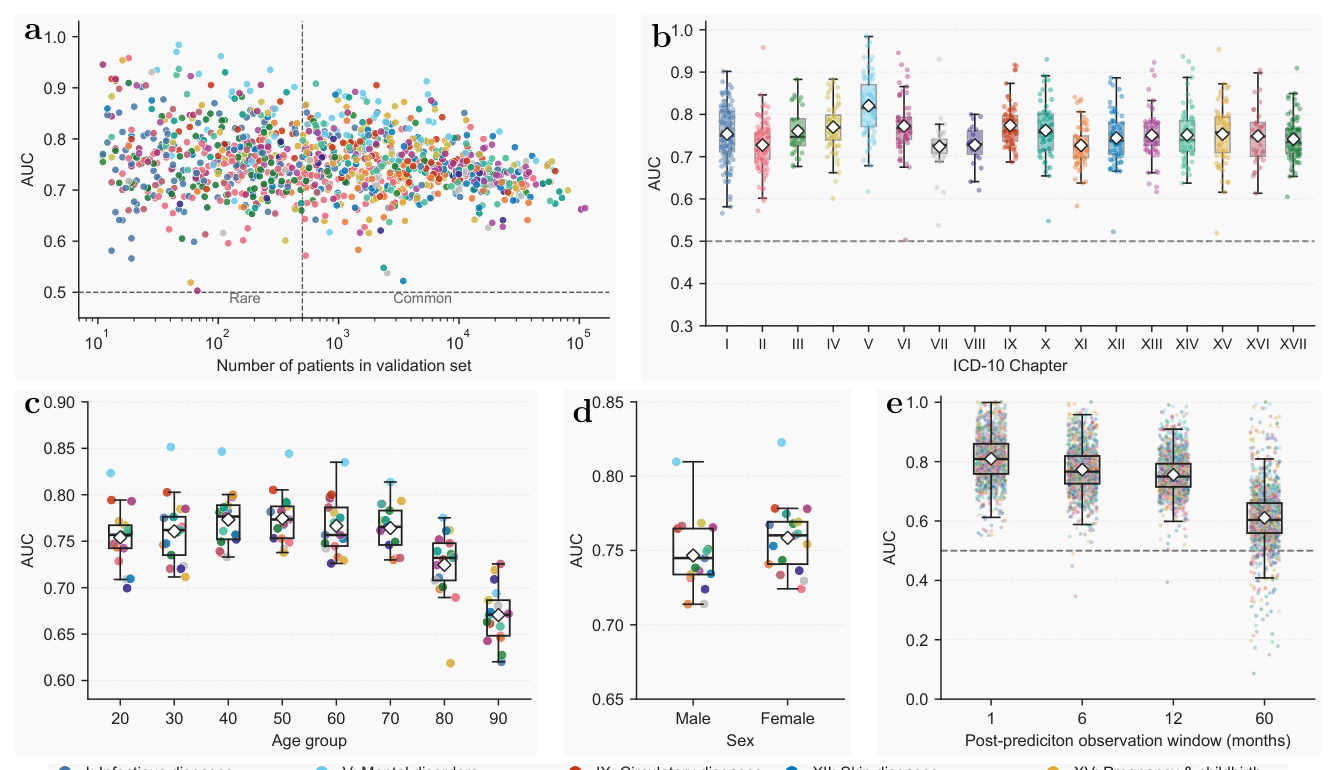
ICD-10 章节级:最强 V. Mental Disorders 82.03%,IX. Circulatory 77.40%,VI. Nervous 77.23%;最弱 VII. Eye 72.41%,XI. Digestive 72.68%,VIII. Ear 72.74%。慢性病、需长期监测的诊疗 pattern 在理赔中可见性高;急诊或依赖影像/病理的疾病可见性低。
年龄层:50 岁段 mean AUC 77.62% 最高,80 岁 72.67%、90 岁 66.25% 下滑——多病共存使 incident label 难与背景 utilization 区分。
性别:女性 75.96%、男性 74.72%,差异微小。
预测期:1 月 80.99% → 6 月 77.30% → 12 月 75.57% → 60 月 61.08%,单调下降但 5 年仍在 random 之上,说明轨迹表征同时支持近期风险分层和长期负担预测。
5.4 医疗支出预测¶
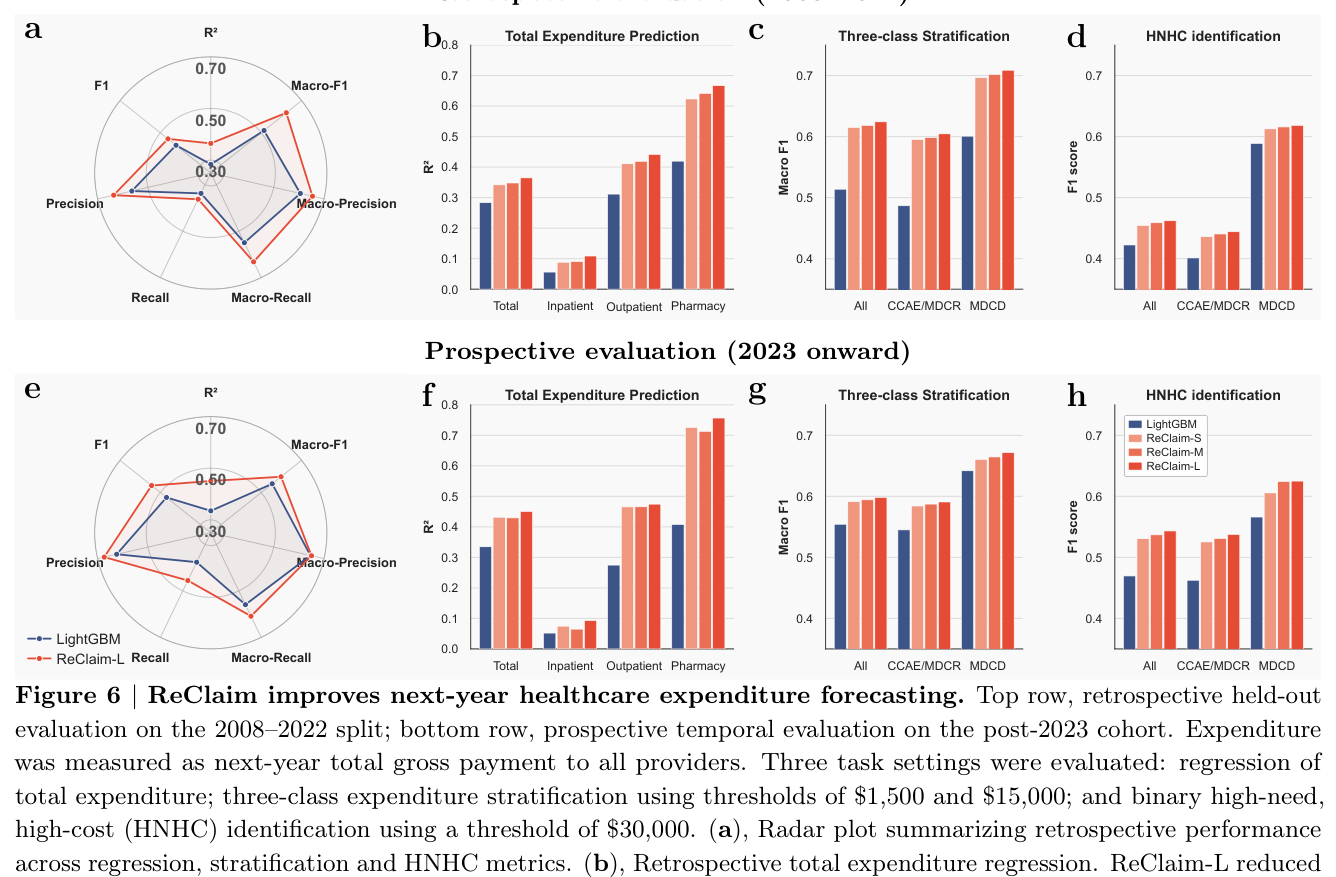
追溯(2008-2022):
| 任务 | 指标 | LightGBM | ReClaim-S | ReClaim-L |
|---|---|---|---|---|
| Total expenditure regression | MAE | 5,871 | 5,115 | 4,982 (15.1%↓) |
| R² | 0.2835 | 0.342 | 0.365 (+28.6%) | |
| Three-class stratification | accuracy | 0.529 | — | 0.660 |
| macro-F1 | 0.514 | — | 0.624 | |
| macro-precision | 0.606 | — | 0.654 | |
| macro-recall | 0.550 | — | 0.632 | |
| HNHC ($30K binary) | F1 | 0.422 | — | 0.462 |
| precision | 0.564 | — | 0.636 | |
| recall | 0.338 | — | 0.363 |
前瞻(2023+):MAE 7,881→7,293(-7.5%),R² 0.335→0.451(+34.6%);HNHC F1 0.470→0.543(precision 0.627→0.670,recall 0.376→0.455)。
分层稳定性:跨支付方(CCAE / MDCR / MDCD)一致改善,MDCD(Medicaid)增益最大——商业保险与 Medicare 上 ReClaim 也都赢,但 Medicaid 群体的 utilization pattern 显然更受益于 large-scale 预训练;按 claim type,pharmacy 改善强,inpatient 改善弱(住院在 monthly 粒度内分布更不规则)。
5.5 Real-World Evidence:因果推断中的偏差控制¶
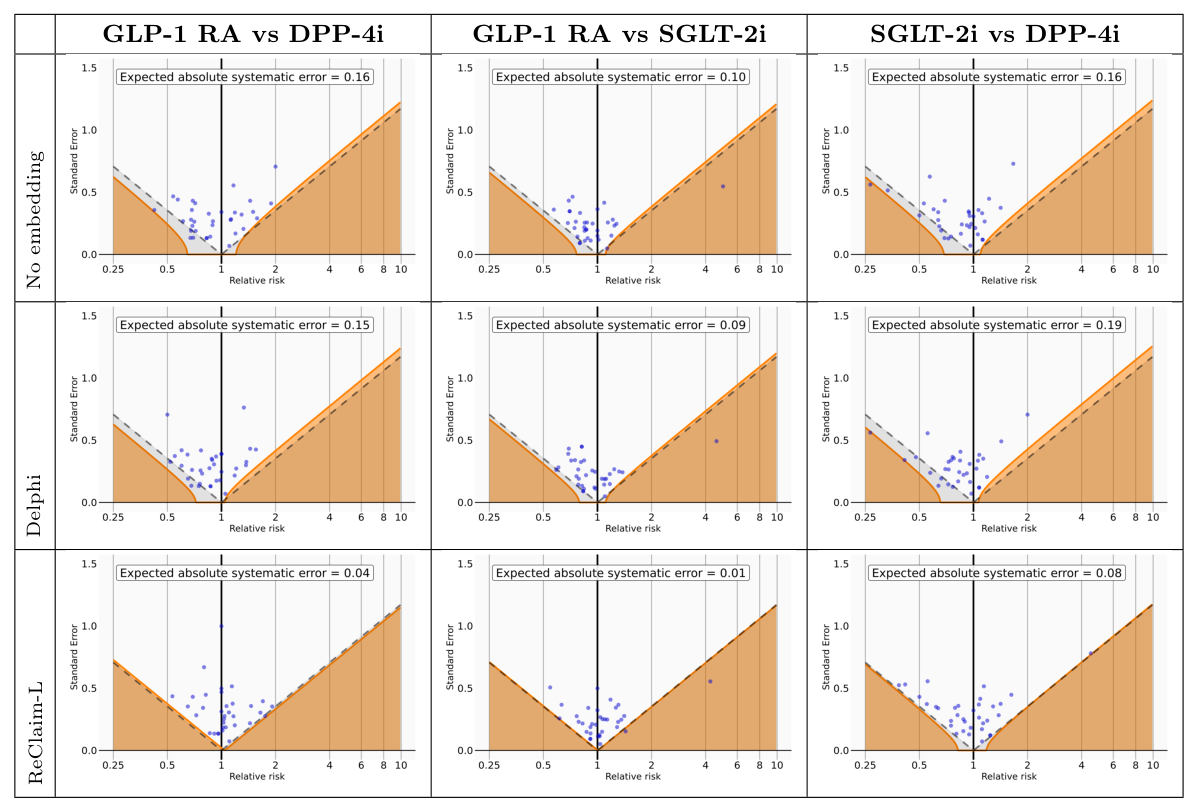
在 7,246 例 GLP-1 RA / SGLT-2i / DPP-4i 比较中,EASE(expected absolute systematic error,越低越好):
| 配对 | No embedding | Delphi | ReClaim-L |
|---|---|---|---|
| GLP-1 vs DPP-4i | 0.16 | 0.15 | 0.04 |
| GLP-1 vs SGLT-2i | 0.10 | 0.09 | 0.01 |
| SGLT-2i vs DPP-4i | 0.16 | 0.19 | 0.08 |
ReClaim-L 把残余系统偏差降低 72%(vs Delphi,GLP-1 vs DPP-4i 配对从 0.16 → 0.04 = 75% 降幅;摘要里给的 72% 是平均)。Equipoise 在 GLP-1 vs DPP-4i 上从 No-embed 68.8% / Delphi 73.6% → ReClaim-L 89.7%,匹配后两组协变量分布重合度提升。
关键洞察:手工定义的临床协变量(age / sex / 用药史 / 共病)只能捕获有限的 confounding;foundation model 的 embedding 把潜在的 longitudinal confounding structure 编码进去,使倾向得分对未观测协变量也更鲁棒——把因果推断和 representation learning 在医疗领域桥接起来。
消融与分析¶
6.1 模型规模 scaling¶
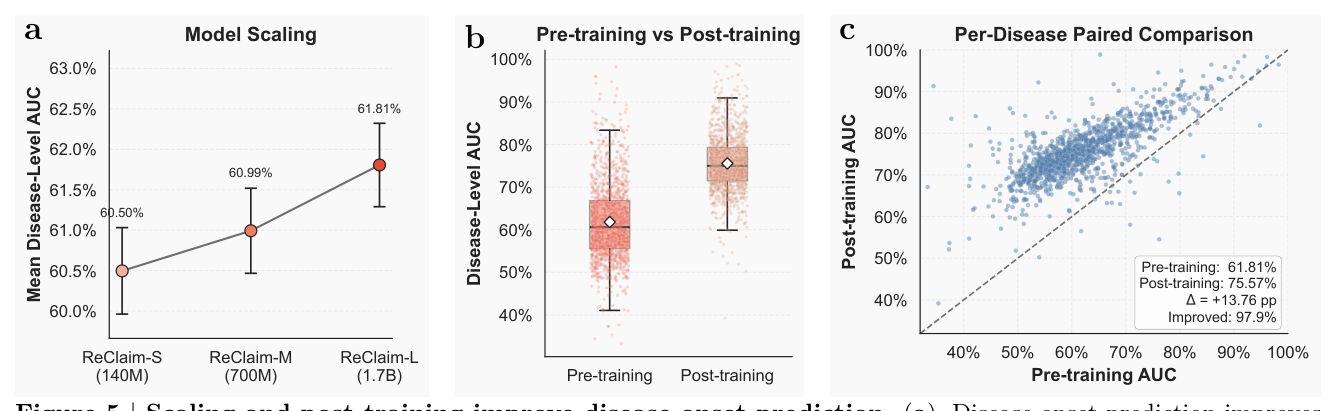
Pre-training only(next-token loss 训练,没有 post-training):
| 模型 | mean disease-level AUC |
|---|---|
| ReClaim-S (140M) | 60.50% |
| ReClaim-M (700M) | 60.99% |
| ReClaim-L (1.7B) | 61.81% |
scaling 单调改善,但绝对增益相对温和(+1.31pp,10× 参数)。增益分布在多数 endpoints而非少数高频疾病——容量改善是系统性的。
6.2 post-training 的巨大贡献¶
ReClaim-L 在 disease onset 上的核心提升来自 post-training:
| 阶段 | mean AUC |
|---|---|
| Pre-training only | 61.81% |
| + Post-training | 75.57% |
| Δ | +13.76pp(95% CI 13.41-14.11,$P=7.1 \times 10^{-195}$) |
post-training 在 97.9% endpoints 上改善,仅 25 个 endpoints 退化(Table A15 显示退化集中在 post-training 数据中代表性低的疾病:B81 hookworm、P13 birth injury、E68 等,prevalence < 0.01%)。
关键效率论点:
- 数据效率:100K 样本 + 1 个 epoch 即获得 +13.76pp;
- 推理效率:免去 Monte Carlo 多条完整序列采样,instruct token 直接读 logits;
- 范式转移:以前的 healthcare FM(Delphi、Curiosity)只靠 pretraining,论文证明类 LLM 的 SFT 范式同样适用于 healthcare claims。
6.3 Temporal resolution ablation(前文 Table 已述)¶
Day / Week / Month 比较中 Month 胜出,但最优粒度是 data- 与 task-specific 的——不能盲目套到 EHR 或更高分辨率源。
6.4 学到的疾病嵌入:UMAP 可视化¶
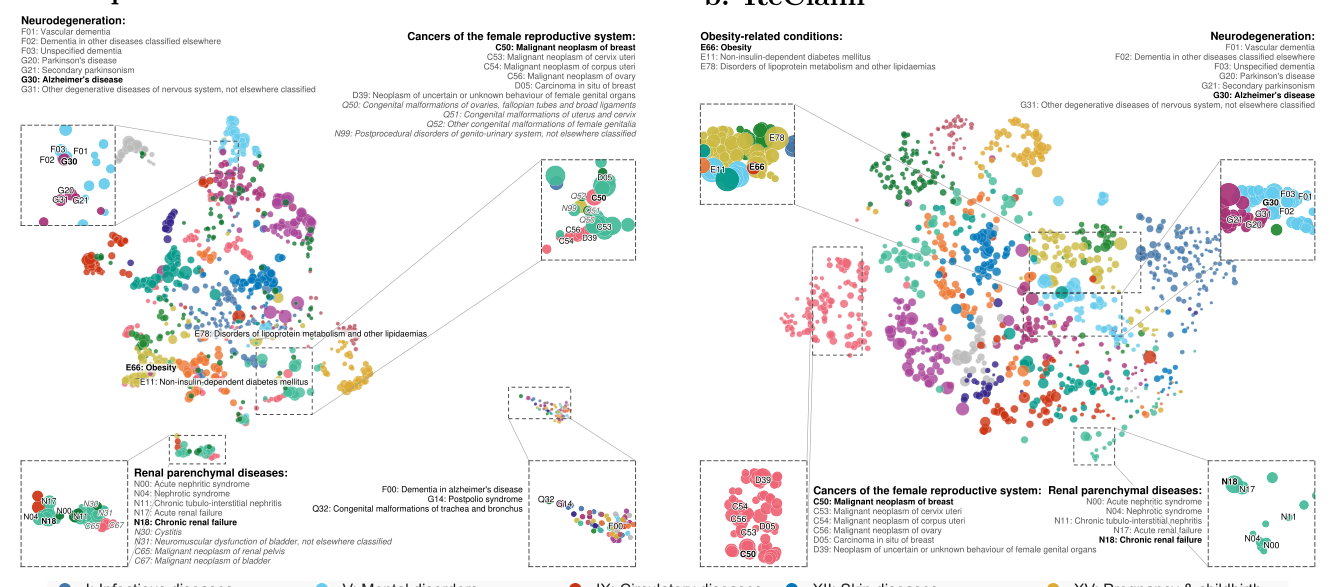
将 ICD-10 疾病 token 的预训练 embedding 投影到二维:
- Delphi:分布弥漫,章节边界模糊。
- ReClaim:major ICD-10 章节占据明确区域,临床相关疾病(神经退行性、肥胖相关、女性生殖肿瘤、肾实质病等)形成紧凑邻域;同时在 metabolic-cardiovascular、respiratory-infectious 间保留跨章节连续性。
定性表明 claim-scale 预训练同时编码语义相似性和共现纵向上下文,胜过纯疾病-incidence 建模。
与已归档相关工作的对比¶
文档库内未找到与 ReClaim 在"healthcare claims foundation model + 大规模预训练 + 任务后训练"问题与解法双同构的论文(archive 主要为推荐系统方向;scaling-laws 类论文虽与 §6.1 中的 scaling discussion 有共性,但问题域与解法骨架均不同构)。本步骤跳过。
讨论与局限性¶
核心贡献¶
- 首次证明 administrative claims 是 healthcare foundation model 的可扩展基质——尽管缺 EHR 的临床细节,但人群规模 + 标准化 + 时间锚清晰给出更稳定的纵向轨迹。
- 统一表征:单个 1.7B 模型同时支持 1208 病预测、支出预测、RWE 因果——多任务通用性比单一 task-specific GBDT / transformer 更广。
- Post-training 范式引入 healthcare:与 Delphi / Curiosity 等纯 pretraining 工作不同,instruct token + response-region 监督在 1 epoch + 100K 样本下贡献 +13.76pp,把 LLM 的 SFT 范式有效迁移过来。
- representation-based RWE:把 foundation model 的 embedding 直接喂给倾向得分模型,使 EASE 大幅下降——为 representation learning 与 causal inference 在医疗领域的融合提供了可扩展路径。
设计上的精妙之处¶
- Tokenizer 三选(temporal resolution、hierarchical code decomposition、cost discretization)都体现"不要直接套 LLM 范式,要根据数据本质做"的实证主义:月聚合让噪声降低、ICD-10 三级分解把 18 万 token 降到 5 千、scientific-notation cost 把跨 9 数量级数值压成 100 个 token。
- Anchor token 的相对/绝对时间双重编码:
<DOBYR-1974>+<AGE-44>+<NY>+<ATT-N>同时给模型相对(间隔)和绝对(出生年、年份)时间信号,比纯位置嵌入更准。 - z-loss 正则化:稳定大规模训练,无需复杂 loss curve 调参。
局限性¶
- 临床细节缺失:claims 没有 lab、影像、临床记录,对依赖这些信号的 endpoint(眼科、消化科、影像确诊)效果较差(章节 AUC 显示)。
- 编码与报销激励偏差:claims 编码受 billing 实践驱动,可能引入系统偏差(如多记并发症提高报销)。
- MarketScan 队列偏差:仅商业、Medicare、Medicaid 入组人,未投保人群被排除;按入组期切片而非人生周期,不能跨多个保险窗连接同一个人。
- 支出与给付方耦合:cost token 受合同价、共付率、福利结构影响,跨支付方系统迁移性受限。
- endpoint 定义粒度:用 ICD-10 三位主码做 broad benchmarking,与 PheCode([25])等 phenotype 系统相比临床一致性不足;后续可换更精细 phenotype。
- 评估覆盖:尚未评估 fairness、interpretability,临床/研究部署仍需更多公平性 / 安全性研究。
未来方向¶
- 与 EHR、影像、基因组数据融合的多模态 healthcare FM。
- foundation model representation 进入 causal inference 框架的系统化研究。
- 模型 interpretability + 公平性(不同人群子群)。
- 将 1.7B 推到更大规模 / 更长上下文(max pos 4096 在长病史情况下可能受限)。
工业落地价值¶
虽然论文背景偏学术(Yale Medical / Trieste / NIH),但应用场景极具产业意义:
- 保险公司:risk adjustment、HNHC 识别(论文 F1 0.422→0.543)、产品定价。
- 药企:target trial emulation、市场准入证据(RWE)。
- 医院系统:长期风险分层、资源规划。
- 1.7B 在合理硬件上 inference 友好,post-training 数据效率高(100K 样本足够),具备真实部署条件。
核心贡献总结¶
ReClaim 把 healthcare foundation model 的边界从"主要在 EHR 上做疾病预测"扩展到"在全美 200M 人理赔上做疾病 + 支出 + 因果推断的统一表征"。三个最值得借鉴的设计点:
- 数据本质驱动的 tokenizer:月聚合 + 层级 ICD 分解 + 科学计数费用,把 180K 词表压到 21K 同时保留全部信息。
- Pretraining + post-training 两阶段:61.81% → 75.57% 跳跃式改善(post-training 仅 100K 样本),证明 LLM SFT 范式在 healthcare claim FM 上同样高效,且通过 instruct token 免去 MC 抽样推理成本。
- Foundation model embedding 用于因果推断:EASE 0.16 → 0.04,把 representation learning 嵌入 RWE 流水线。