Dynamic Short Convolutions Improve Transformers¶
Oliver Sieberling¹, Bharat Runwal², Rameswar Panda², Yoon Kim¹ ¹Massachusetts Institute of Technology ²MIT-IBM Watson AI Lab arXiv:2606.03825v1 · 2026-06-02 · 开源 Triton 内核:https://github.com/OliverSieberling/dynamic-conv1d
研究动机与背景¶
深度学习架构由一组「原语(primitive)」搭建而成——多层感知机、卷积、循环层、注意力,再辅以残差连接和归一化。Transformer 之所以成为大语言模型(LLM)的主导架构,正是因为它把注意力、前馈层、残差、归一化等原语组合成了一个可扩展且灵活的模型。本文的核心主张是:动态短卷积(dynamic short convolution)是一种值得加入 Transformer 的新原语,它能在保持卷积「局部性归纳偏置」的同时,通过输入依赖的滤波器显著提升表达力,并且可扩展、硬件高效。
要理解动机,需要回顾卷积在 NLP 中的历史。一维卷积曾长期作为序列建模的「序列混合(sequence mixing)」组件,从早期的词级标注、句子分类,到序列到序列学习和语言建模都有应用,但在 Transformer 出现后基本退出了主流。后 Transformer 时代,一些工作发现把轻量级的深度可分离卷积(depthwise separable convolution)——也称短卷积(short convolution)——重新引入 Transformer,在某些设定下能提升性能(So et al. 2021 的 Primer;Allen-Zhu 2025 的 Canon 层)。值得注意的是,短卷积已经是现代线性 RNN(Mamba、DeltaNet)序列混合器的标准组件。然而据作者所知,短卷积尚未成为前沿开源 LLM 的标配。
短卷积的局限在于它是静态的:同一组滤波器权重在所有时间步上共享,施加了固定的局部聚合规则,无法根据内容自适应。论文用一个语言学例子说明为什么这不够:考虑短语 "the old can opener"(名词短语,结构 [the [old [can opener]]])与 "the old can swim"(动词短语,结构 [[the old] [can swim]])。两者前缀完全相同,但对这个 4 词窗口的局部组合方式取决于最后一个词("opener" vs "swim")。静态卷积有局部性偏置但无法显式建模这种输入依赖的局部组合;堆叠的注意力层原则上能用位置信息以上下文相关的方式组合局部上下文,但代价高且缺乏局部性归纳偏置。动态卷积恰好适合建模这类现象。
作者明确了一个层要「实用」必须满足的 scalability(可扩展性)三要素: 1. 模型与数据规模增大时,该层应持续带来增益; 2. 由于新层通常引入更多算力/参数,它必须提高整体的「算力换性能」效率——即算力/参数匹配时仍优于现有架构; 3. 该层应硬件高效,能在 GPU/TPU 上高效训练。
本文证明动态短卷积同时满足上述三条。横跨 150M–2B 参数的实验里,动态卷积持续优于标准 Transformer 以及加了静态短卷积的 Transformer;拟合 scaling law 表明:当动态卷积加在 Q/K/V 上时有 1.33× 的算力优势,加在所有线性层之后时有 1.60× 的算力优势。配合自研 Triton 内核,端到端训练的额外开销可控(QKV 变体约 8% 减速,全线性变体在 2B 规模约 22% 减速)。
核心方法:动态短卷积¶
参数化(Parameterization)¶
静态短卷积是一个卷积核宽度为 $W$(语言任务常取 $W \in \{3,4,5\}$)的深度可分离卷积,沿时间维施加。对激活序列 $x_t \in \mathbb{R}^D$,滤波器 $w \in \mathbb{R}^{W \times D}$:
$$y_t := \sum_{k=0}^{W-1} w_k \odot x_{t-k} \tag{1}$$
其中 $\odot$ 是逐元素乘积。关键是卷积权重 $w$ 在时间轴上固定。
动态短卷积把卷积核变成输入依赖的。在每个位置 $t$,一个权重生成器(例如一个线性投影)产生动态卷积权重 $w^{(t)} \in \mathbb{R}^{W \times D}$,然后用这个时变滤波器做卷积:
$$y_t := \sum_{k=0}^{W-1} w_k^{(t)} \odot x_{t-k} \tag{2}$$
这样每个 token 都「挑选自己的滤波器」去从局部上下文里检索信息。这一点上动态卷积与注意力有相似之处,但区别在于:注意力的权重来自 query–key 相似度(参考被检索内容),而动态卷积直接从查询位置本身生成权重(不参考被检索内容),它带有强烈的「按相对位置检索」的归纳偏置。
参数高效化。朴素地产生动态卷积权重需要一个 $D \to W\cdot D$ 的线性投影,当 $W=4$ 时大约会让底层模型的参数翻倍。论文给出两种更省参的参数化:
- 低秩(low-rank)参数化:把投影分解为秩为 $R$ 的低秩变换,即 $D \to R \to W\cdot D$。
- head-wise 参数化:把维度分到不同的「头(head)」,用变换 $D \to W\cdot(D/H)$,每个权重在大小为 $H$ 的头内广播共享。
作者发现低秩参数化通常性能更好,但 head-wise 变体更利于设计高效 GPU 内核。上述变换都带 bias,因此滤波器是输入的仿射变换。
放置位置(placement)。主实验中,动态短卷积放在 Q、K、V 上、RoPE 之前,卷积核宽度 $W=4$,并以残差方式施加:
$$X = X + \mathrm{dynamicShortConv}(X), \quad X \in \{Q, K, V\} \tag{3}$$
生成动态卷积权重的投影以注意力归一化后的激活作为输入(作者发现这比直接拿 $Q,K,V$ 本身做输入略好,且能与 qkv_projection 融合)。作者还实验了把动态卷积放在 Transformer 所有线性层之后的变体。
高效训练(Triton 内核)¶
动态短卷积的算术强度低,是访存受限(memory-bound)的。朴素的 PyTorch 实现会反复把中间张量在 HBM 之间搬运,导致实际很慢。作者用自研 Triton 内核解决:内核一次性读入激活和动态卷积权重,在片上(on-chip)完成整个卷积,只把最终结果写回 HBM。每个输入只读一次、每个输出只写一次,性能主要被 HBM 带宽限制。
关键观察:动态权重张量形状为 $B \times T \times D \times W$,比激活张量 $B \times T \times D$ 大了 $W$ 倍,主导了 HBM 流量。因此减小动态卷积权重的尺寸能直接降低延迟。head-wise 动态卷积让 $H$ 个连续通道共享同一组滤波器,把权重张量缩小到 $B \times T \times (D/H) \times W$;当 $H \gg W$ 时,其 IO 开销相对激活可以忽略。
对低秩参数化,作者还开发了一个把第二个投影直接融合进卷积内核的 Triton 内核:它不读取已物化的 $B\times T\times D\times W$ 动态权重,而是读入低秩输入 $z$($B\times T\times R$)和第二投影 $U$($R\times(D\cdot W)$),在片上生成动态权重 $zU$ 并立即施加卷积。动态权重从不写回 HBM,因此低秩内核显著快于 head-size-1 内核。
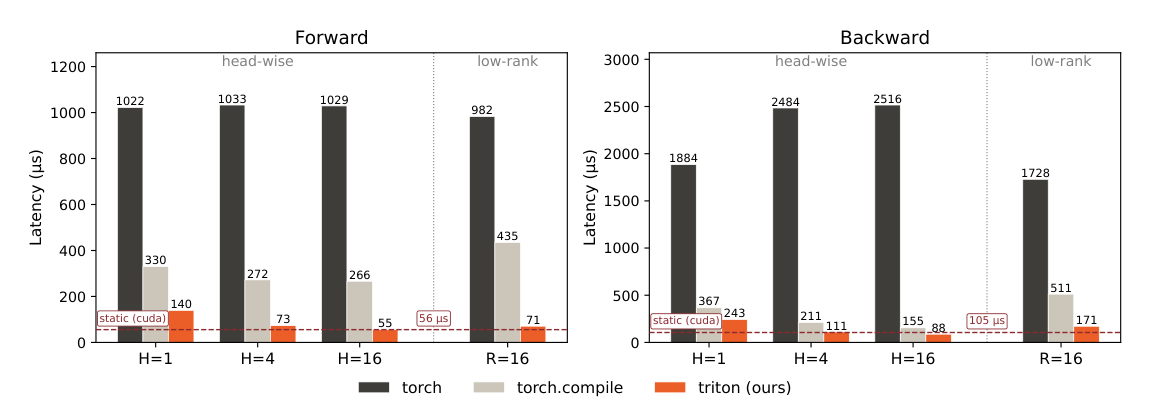
实测结果:在全部四种配置上,本文 Triton 内核比最好的 torch.compile 基线(前向+反向)快 1.8–3.9×。延迟随 head-size 增大而下降;当 $H=16$ 时甚至比 CUDA 优化的静态卷积实现还快。head-wise 内核能跑出 2.6–3.0 TB/s 的 HBM 流量(理论峰值 3.35 TB/s)。低秩内核延迟低于 head-size-1 内核(尽管它还多融合了一个线性投影),证明了避免物化动态权重的好处。总体而言,本文动态短卷积内核只比 CUDA 优化的静态短卷积核(state-of-the-art)稍慢一点($H\ge16$ 时甚至更快)。
实验设置¶
所有模型在 lm-engine 代码库中、用 Nemotron-CC 语料、Granite-4 BPE tokenizer(词表 100,352)训练。统一设定:序列长度 4096、RMSNorm、SwiGLU MLP、RoPE、Llama 风格 pre-norm block。优化器 AdamW,峰值学习率 $3\times10^{-4}$,weight decay 0.1,10% warmup + 余弦衰减到 0。稠密模型规模取 $\{150M, 300M, 600M, 1B, 2B\}$,token/参数比约 50(即 Hoffmann et al. 2022 计算最优配方的 2.5×);另外训练一个 7B(1B 激活)的 MoE 模型,训练 100B token。
主要实验结果¶
合成基准:变长 key 的关联召回¶
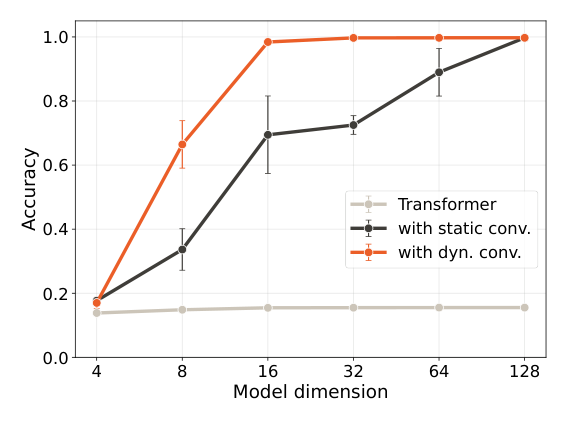
作者用一个修改版的多查询关联召回(MQAR)任务来诊断局部上下文组合能力。标准 MQAR 提供一串 (key, value) 对各出现两次,监督模型在 key 第二次出现时预测对应 value。本文的修改是:每个 key 由可变数量的 token 组成($L_k \in \{1,2,3\}$),后接一个编码 $L_k$ 的分隔符 token,再接单个 value token。例如一个 key(bc)可能是另一个 key(abc)的后缀,因此成功检索必须依赖动态滤波器——由于不同 key 共享 token 且长度不同,没有任何静态滤波器能把它们分开。
用单层单头 Transformer、卷积宽度 $W=4$(刚好覆盖整个 key)、低秩 $R=16$,训练 100,000 个样本,取 5 个种子中位数。如 Figure 2(左)所示,在相同模型尺寸下,带动态短卷积的 Transformer 全面优于带静态卷积和不带卷积的 Transformer,凸显了输入依赖的局部组合的价值。
作者还在 MAD(mechanistic architecture design)诊断基准上测试(也用 $R=16$),结果见下表(Figure 2 右):
| Task | Transformer | w/ static conv. | w/ dyn. conv. |
|---|---|---|---|
| Compress | 0.375 | 0.417 | 0.424 |
| Fuzzy Recall | 0.298 | 0.505 | 0.726 |
| In-Context Recall | 0.942 | 1.000 | 1.000 |
| Memorize | 0.791 | 0.856 | 0.795 |
| Noisy Recall | 0.917 | 1.000 | 1.000 |
| Selective Copy | 0.930 | 0.983 | 0.988 |
| Average | 0.709 | 0.793 | 0.822 |
结论分析:动态卷积在 MAD 上整体表现最好,提升在 Fuzzy Recall(0.505→0.726)上尤其显著——该任务要求在 key/value 由可变 token 数组成的设定下做上下文召回,正对应动态卷积「输入依赖的可变长局部聚合」的能力。Memorize 上略逊于静态卷积,说明纯记忆任务并不受益于动态性。
语言建模 scaling laws¶
这是论文最核心的证据。对动态卷积用低秩版本、秩 $R = \{20,26,32,42,52\}$ 分别匹配 $\{150M,300M,600M,1B,2B\}$ 模型,拟合验证损失关于算力的 scaling 曲线。
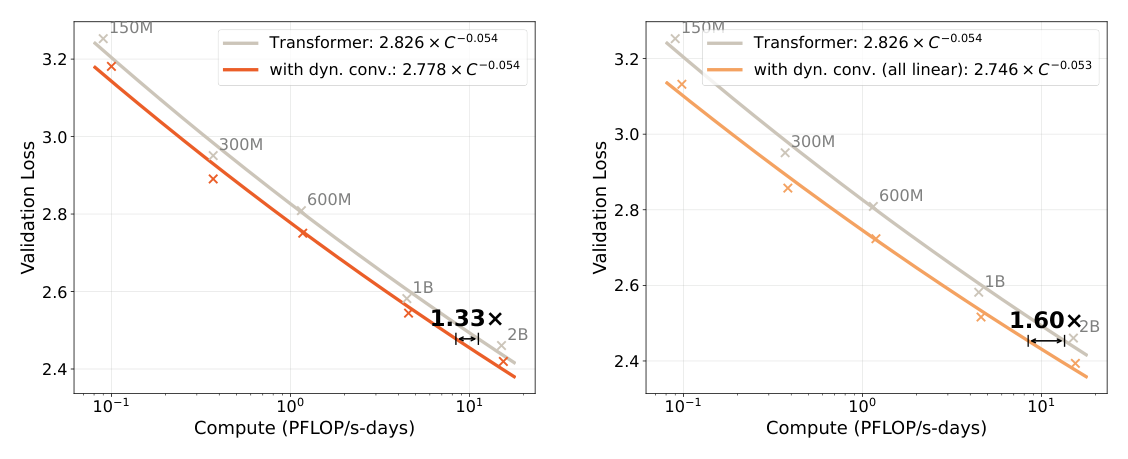
- 左图(Q/K/V 放置):Transformer 拟合 $2.826\times C^{-0.054}$,带动态卷积拟合 $2.778\times C^{-0.054}$,水平方向算力优势约 1.33×——即达到相同损失只需 1/1.33 的算力。
- 右图(所有线性层后放置):带动态卷积(all linear)拟合 $2.746\times C^{-0.053}$,算力优势提升到 1.60×。
结论分析:两条曲线指数几乎相同(约 −0.054),说明动态卷积主要是把损失曲线整体下移(改善常数因子),而非改变 scaling 指数。把动态卷积铺到每个线性层之后能把 1.33× 提升到 1.60×,证明这个原语的收益可以通过更密集地放置来累积。
端到端训练吞吐¶
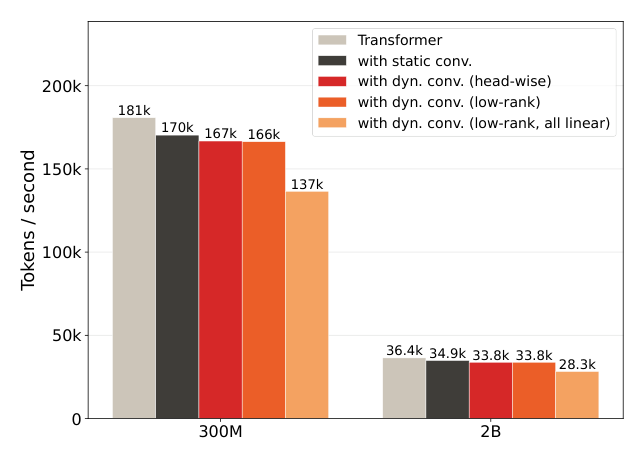
| 配置 | 300M (tokens/s) | 2B (tokens/s) |
|---|---|---|
| Transformer | 181k | 36.4k |
| w/ static conv. | 170k | 34.9k |
| w/ dyn. conv. (head-wise) | 167k | 33.8k |
| w/ dyn. conv. (low-rank) | 166k | 33.8k |
| w/ dyn. conv. (low-rank, all linear) | 137k | 28.3k |
结论分析:两种动态卷积变体(QKV 放置)相对 Transformer 基线的额外开销都控制在 8% 以内,而静态卷积本身就有约 6% 的减速——也就是说动态卷积相对静态卷积几乎不增加额外成本。全线性变体的开销较大(约 22–25% 减速),但作者指出可通过把动态卷积融进 matmul epilogue 进一步降低内存 IO。考虑到 1.33× 的 scaling 优势,即便有当前的吞吐惩罚,墙钟时间上仍有显著净收益。
下游评测(Table 1)¶
在 (roughly) 300M(15B token)、2B(100B token)、7B/1B 激活 MoE(100B token)上做困惑度(held-out Nemotron-CC、Wikitext-103、LAMBADA)与 11 个 lm-eval-harness 0-shot 任务平均。下表节选主要行:
| Model | Train | Params | Conv Loc | Nemo.↓ | LAMB.↓ | Wiki.↓ | Task Avg↑ |
|---|---|---|---|---|---|---|---|
| MoE Transformer | 100B | 6.77B | – | 9.86 | 11.55 | 13.27 | 62.46 |
| w/ static conv. | 6.77B | QKV | 9.74 | 11.20 | 13.08 | 62.97 | |
| w/ dyn. conv. (head-wise) | 6.80B | QKV | 9.65 | 11.61 | 12.90 | 63.43 | |
| w/ dyn. conv. (low-rank) | 6.80B | QKV | 9.58 | 10.92 | 12.77 | 63.42 | |
| Transformer | 100B | 1.82B | – | 11.71 | 17.28 | 15.86 | 58.35 |
| w/ more params (wider FFN) | 1.87B | – | 11.67 | 18.49 | 15.72 | 58.23 | |
| w/ static conv. | 1.83B | QKV | 11.50 | 16.21 | 15.43 | 58.94 | |
| w/ dyn. conv. (head-wise) | 1.88B | QKV | 11.41 | 16.34 | 15.23 | 58.46 | |
| w/ dyn. conv. (low-rank) | 1.88B | QKV | 11.24 | 14.98 | 15.43 | 59.70 | |
| w/ dyn. conv. (low-rank) | 1.88B | all linear | 10.95 | 12.51 | 14.43 | 60.70 | |
| Transformer | 15B | 305.2M | – | 19.12 | 76.62 | 30.50 | 47.26 |
| w/ more params (wider FFN) | 311.5M | – | 18.99 | 68.05 | 30.04 | 46.64 | |
| w/ static conv. | 305.4M | QKV | 18.66 | 69.64 | 29.50 | 46.86 | |
| w/ dyn. conv. (low-rank) | 311.8M | QKV | 18.01 | 56.66 | 27.98 | 48.90 | |
| w/ dyn. conv. (low-rank) | 319.0M | all linear | 17.42 | 46.13 | 26.78 | 48.81 |
结论分析:(1)静态卷积普遍优于普通 Transformer,但低秩与 head-wise 动态卷积在所有参数规模上都在困惑度和任务准确率上进一步超越静态卷积;(2)「all linear」放置带来进一步增益;(3)「wider FFN」对照组说明动态卷积的增益不是单纯多加参数带来的——同样多加参数去拓宽 FFN,效果远不如把参数花在动态卷积上(如 1.82B Transformer 加宽 FFN 后 LAMBADA 反而从 17.28 恶化到 18.49)。
线性注意力变体(Mamba-2 / Gated DeltaNet)¶
现代线性 RNN(Mamba、DeltaNet)的序列混合器里已经包含静态深度可分离短卷积作用于 Q/K/V。作者测试:把这些静态卷积替换成动态卷积是否进一步改进架构?Table 1 底部给出 300M/15B-token 结果:
| Model | Conv Loc | Nemo.↓ | LAMB.↓ | Wiki.↓ | Task Avg↑ |
|---|---|---|---|---|---|
| Gated DeltaNet (w/o conv.) | – | 18.93 | 69.90 | 30.24 | 46.93 |
| w/ static conv. | QKV | 18.75 | 67.63 | 29.82 | 46.76 |
| w/ dyn. conv. (head-wise) | QKV | 18.03 | 59.99 | 28.17 | 47.27 |
| w/ dyn. conv. (low-rank) | QKV | 17.95 | 50.56 | 27.95 | 49.22 |
| Mamba-2 (w/o conv.) | – | 20.26 | 80.81 | 33.26 | 46.41 |
| w/ static conv. | QKV | 19.30 | 83.50 | 31.32 | 45.78 |
| w/ dyn. conv. (head-wise) | QKV | 18.69 | 65.80 | 30.03 | 47.24 |
| w/ dyn. conv. (low-rank) | QKV | 18.72 | 71.12 | 29.90 | 47.34 |
结论分析:移除静态卷积会让困惑度变差(印证其作用),而用动态卷积替换静态卷积在所有数据集上显著改善困惑度。一个有意思的发现:带动态卷积的 Mamba-2 表现接近带静态卷积的 Gated DeltaNet——这暗示「给序列混合器加动态短卷积」可能比「重新设计序列混合器本身」更划算。
长上下文:RULER(Table 2)¶
在 RULER 基准(上下文长度 4096)上分析 MoE 模型的逐子任务表现:
| Model | S1 | S2 | S3 | MK1 | MK2 | MK3 | MQ | MV | CWE | FWE | VT | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MoE Transformer | 99.8 | 100.0 | 83.8 | 70.0 | 4.8 | 21.2 | 39.4 | 32.0 | 26.4 | 43.3 | 9.3 | 48.2 |
| w/ static conv. | 100.0 | 100.0 | 73.8 | 72.0 | 27.6 | 6.0 | 36.5 | 40.8 | 13.3 | 26.8 | 23.9 | 47.3 |
| w/ dyn. conv. (head-wise) | 100.0 | 99.8 | 81.8 | 74.2 | 45.4 | 38.4 | 37.4 | 40.5 | 15.1 | 16.3 | 8.1 | 50.6 |
| w/ dyn. conv. (low-rank) | 99.8 | 100.0 | 93.0 | 66.2 | 12.8 | 11.8 | 48.2 | 50.4 | 31.1 | 26.4 | 18.4 | 50.7 |
结论分析:动态卷积在 multi-key(MK)、multi-query(MQ)、multi-value(MV) 子任务上表现尤其突出——这与「动态卷积擅长输入依赖的局部聚合」的直觉一致(这些子任务需要在局部窗口内对多个键/值做内容相关的聚合)。
消融分析(Table 3)¶
全部基于 300M / 15B-token 模型,报告 Nemotron-CC 困惑度(PPL)。
(a) 宽度 W / head size H / 秩 R 扫描:
| Sweep | PPL | Sweep | PPL | Sweep | PPL | ||
|---|---|---|---|---|---|---|---|
| W=1 | 18.42 | H=8 | 18.03 | R=4 | 18.26 | ||
| W=2 | 18.17 | H=16 | 18.08 | R=8 | 18.19 | ||
| W=3 | 18.08 | H=32 | 18.21 | R=16 | 18.10 | ||
| W=4 | 18.10 | H=64 | 18.25 | R=32 | 18.04 | ||
| W=5 | 18.09 | H=128 | 18.40 | R=64 | 17.87 | ||
| W=6 | 18.10 | R=128 | 17.85 |
结论分析:宽度 $W=3$ 或 $4$ 是甜区(与静态卷积的结论一致),更宽即使增加参数也不再带来收益。head-wise 变体里更小的 head(更多头)性能更好但参数更多。低秩变体里增大 $R$ 单调改善性能但代价是更多参数——这说明秩 $R$ 提供了一条用参数换性能的额外坐标轴;$R=16$ 在性能与参数量之间是个不错折中。
(b) 层内放置(low-rank R=16, W=4):
| Placement | PPL | Placement | PPL | |
|---|---|---|---|---|
| Transformer (无 conv) | 19.12 | Q+K | 18.44 | |
| Q only | 18.69 | Q+V | 18.36 | |
| K only | 18.83 | K+V | 18.35 | |
| V only | 18.56 | Q+K+V | 18.10 |
结论分析:单投影里 V 的收益最大(18.56);用到两个投影进一步改善;Q+K+V 三者全用效果最好,因此主实验采用 Q+K+V 放置。
(c) QK-norm Transformer:当前前沿开源 LLM 越来越多采用 QK-norm。在带 QK-norm 的 Transformer 上:
| Setup | PPL |
|---|---|
| Transformer with QK-Norm | 18.69 |
| w/ static conv. | 18.56 |
| w/ dyn. conv. (head-wise) | 18.30 |
| w/ dyn. conv. (low-rank) | 17.95 |
结论分析:在 QK-norm Transformer 上动态卷积依然带来显著增益,而静态卷积此时收益很小。这对实用性很重要——说明动态卷积能与现代前沿配方(QK-norm)兼容叠加。
核心贡献总结¶
- 提出动态短卷积作为 Transformer 的新原语:通过从当前隐藏状态生成输入依赖的卷积滤波器,在保留卷积局部性归纳偏置的同时增强表达力,弥补静态短卷积「固定局部组合规则」的缺陷。
- 系统验证 scalability 三要素:跨 150M–2B 稠密 + 7B/1B-激活 MoE,动态卷积持续优于带/不带静态卷积的 Transformer;scaling law 给出 1.33×(QKV)/ 1.60×(all linear) 的算力优势。
- 硬件高效的 Triton 内核:head-wise 与低秩两套内核,比最佳 torch.compile 基线快 1.8–3.9×,端到端训练额外开销可控(QKV ~8%,all-linear ~22%)。
- 跨架构可迁移:把线性 RNN(Mamba-2、Gated DeltaNet)里的静态卷积换成动态卷积同样显著改善,暗示「加动态短卷积」可能比「重设计序列混合器」更划算。
- 与现代配方兼容:在 QK-norm Transformer 上仍有显著增益。
讨论与局限性¶
值得借鉴的设计。动态短卷积本质是一个「轻量、输入依赖、带局部性偏置」的序列混合算子,与注意力互补而非替代:注意力做全局、内容相关的检索,动态卷积做局部、位置相关的组合。三个工程亮点尤其值得吸收:(1)低秩 / head-wise 参数化把朴素的「参数翻倍」压到可接受范围,且低秩还提供 scaling 的额外坐标轴;(2)把第二投影融进卷积内核、动态权重永不写回 HBM 的内存优化思路,对所有 memory-bound 的逐 token 生成算子都通用;(3)用 scaling law 的水平算力优势(1.33×) 而非单点指标来论证一个原语的价值,方法论上更有说服力。
对推荐序列建模的潜在迁移价值。虽然论文完全在 LLM/语言建模语境下展开,没有任何推荐实验,但其核心机制——「为序列中每个位置生成输入依赖的局部聚合滤波器」——与生成式推荐里日益重要的「长行为序列建模」高度相关。生成式推荐架构(HSTU 谱系)同样依赖序列混合器,且同样面临「如何在 scaling 时同步扩充序列建模能力」的问题;动态短卷积作为一个即插即用、可叠加在注意力/线性注意力之上的局部算子,理论上可迁移到推荐场景的行为序列编码。这也是本文被纳入精读的主要理由(通用 LLM 技术的横向借鉴),而非它本身属于推荐方向。
局限性。作者本人坦诚指出:(1)规模上限有限——scaling 研究只到 2B 稠密 / 7B-激活 MoE,足以建立一致趋势,但不足以独立证明同样的算力优势会在前沿规模、更长训练、不同数据混合/tokenizer 下成立;(2)推理优化不足——虽然 Triton 内核让训练实用,但要完全优化推理、支持更广硬件、更激进地融合动态与静态组件,还需额外工程;(3)设计空间探索有限——只覆盖了参数化、放置、卷积宽度的一小部分组合。
方法论可扩展性评价。从「参数量 scaling 时表征能力与序列建模能力能否一起增长」的角度看,本方法是健康的:动态滤波器由隐藏状态生成,表征容量随模型宽度增长;不存在「先离线压缩再在线建模」式的两阶段解耦,也没有会固化下游表征空间的冻结码本。但需要注意,核心 insight(输入依赖的卷积滤波器)并非全新——Wu et al. 2019 的 lightweight/dynamic convolution 已在 NLP 里提出动态卷积替代自注意力,ConvBERT 用 span-based 动态卷积替换部分 BERT 注意力头。本文的贡献更偏向在现代前沿 Transformer 配方上对这一谱系做严谨的 scaling 刻画 + 高效内核工程 + 跨架构验证,而非提出一种全新机制。综合其扎实的实验严谨度、明确但增量的新颖度、缺乏线上部署与前沿规模验证,定位为一篇高质量的架构原语研究工作。