CS3: Efficient Online Capability Synergy for Two-Tower Recommendation¶
研究动机与背景¶
工业级推荐系统普遍采用多阶段流水线:早期召回(retrieval)阶段需在严格算力预算下从海量候选池中挑选初筛集合,随后经由粗排、精排、重排等阶段逐级精化。双塔模型(two-tower) 是召回阶段的主流架构:用户塔 $U_{\theta_u}$ 与物品塔 $V_{\theta_v}$ 各自独立地把原始特征编码为稠密向量 $u, v$,相关性由点积或余弦相似度计算,即 $p = u^\top v$。这种设计使得用户向量可以在请求时计算一次反复使用,物品向量可离线预计算并缓存,并可借助 FAISS 等库进行近似最近邻搜索,大幅降低线上开销。
尽管双塔结构在效率上具有天然优势,CS3 作者指出它在召回质量上有三个结构性瓶颈,并非简单增大参数量就能缓解:
- 容量不足(Capacity):为了满足 ms 级延迟预算,每塔通常采用轻量 MLP 或浅层 Transformer。相比下游的精排,双塔单边的表达能力先天受限。
- 对齐困难(Alignment):用户塔与物品塔在相似度计算之前不发生任何交互,仅靠训练目标(通常是对比 loss 或二分类 loss)去保证两个向量空间对齐。在工业规模下这种隐式对齐往往不足,尤其在在线学习场景中,数据分布持续漂移,隐式对齐更难跟上。
- 跨阶段一致性差(Cross-stage consistency):下游精排可以充分利用用户-物品交叉特征(如 CAN [1])和 target-aware 的序列建模(如 TWIN [5]、SIM [19]),但这些信号都没有传递给召回塔;召回塔与精排塔建模的"是否相关"在结构上处于两个不同的假设空间,形成端到端优化的结构鸿沟。
现有工作通常沿单一轴线做改进:要么通过隐式交叉塔交互(如 IntTower [14]、双增强双塔 [29])增强对齐,要么通过知识蒸馏(Ranking Distillation [20, 23])让召回塔去逼近一个更强的 teacher。但这些方案有三个局限:(i) 通常增加额外的服务延迟或不易工程化;(ii) 在在线学习约束下(新 item 持续出现,模型每 ~30 分钟更新一次参数)尤其难以部署,因为蒸馏式方案需要频繁重训 teacher;(iii) 不存在一个统一机制同时解决上述三种瓶颈。
基于此,本文提出 Capability Synergy(CS3)——一个即插即用的"能力协同"范式,把召回增强建模为 三种能力交换(capability exchange):(1) 塔内自我修正,(2) 跨塔同步,(3) 来自下游 cascade 模型的跨阶段知识复用。CS3 不改变双塔的主体架构,只在 FC 层与输入端注入轻量模块,因此能保留双塔的在线服务预算(ms 级延迟、向量可缓存、FAISS 友好),且与多种双塔 backbone 兼容。
本文的贡献总结为三点:
- 框架创新:CS3 首次把"塔内精化 + 跨塔对齐 + 跨阶段知识复用"三个彼此正交的增强方向,统一到一个能力协同范式中,避免了堆砌"单点 trick"带来的边际收益递减。
- 协同模块:CS3 实例化为三个轻量模块——Cycle-Adaptive Structure(CAS)、Cross-Tower Synchronization(CTS)、Cascade-Model Sharing(CMS)——它们可以嵌入到标准双塔架构中,对系统侧改动极小。
- 工业级验证:作者在严格延迟约束下,把 CS3 实现于一个在线学习的广告系统,通过离线实验(3 个公开数据集)和在线 A/B(3 个业务场景)共同验证其一致性收益。
核心方法:CS3 框架概览¶
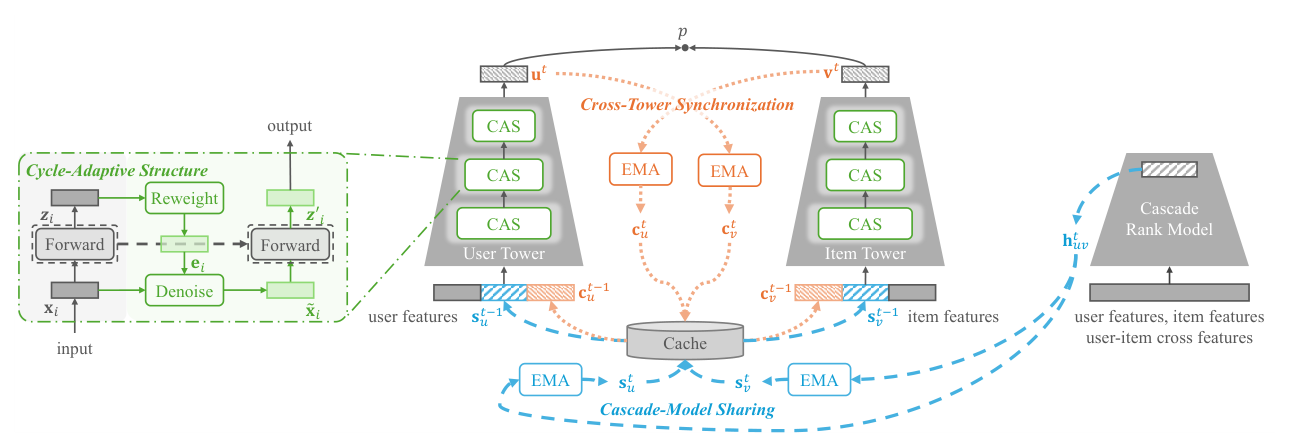
如 Figure 1 所示,CS3 在标准双塔骨架上叠加三条独立但互补的信息通路:
- 绿色 CAS 部分:嵌入每一层 FC 内部,实现塔内的"预前向 → 自适应重加权 → 再前向"循环自修正;
- 橙色 CTS 部分:通过 EMA 缓存对侧塔的表示 $c_u, c_v$,并注入到下一步两塔的输入中,实现跨塔显式交换;
- 蓝色 CMS 部分:通过 EMA 缓存下游 cascade 排序模型的中间表示 $s_u, s_v$,同样注入到双塔输入中,实现跨阶段知识复用。
三条通路共享相同的"预测–重加权–合并"设计思想,但作用范围逐级扩大:塔内 → 跨塔 → 跨阶段。下面分别展开各模块。
Cycle-Adaptive Structure(CAS)¶
动机。双塔单边通常是一个多层 MLP;每一层 FC 对输入特征的噪声敏感。作者借鉴了 RecycleNet [12, 22] 与扩散模型 [9, 21] 中"循环自精化 / 迭代去噪"的思路,用 CAS 替换标准 FC 层,为每层增加一次轻量自修正循环。一次循环由三步构成:pre-forward、adaptive reweighting、cycle-forward。
Pre-Forward。设 $\mathbf{x}_i \in \mathbb{R}^{d_i}$ 是第 $i$ 层输入,第一次前向:
$$ \mathbf{z}_i = f_{\theta_i}(\mathbf{x}_i) = \sigma(\mathbf{W}_i \mathbf{x}_i + \mathbf{b}_i) \tag{1} $$
其中 $f_{\theta_i}: \mathbb{R}^{d_i} \to \mathbb{R}^{d_{i+1}}$,参数 $\theta_i = \{\mathbf{W}_i \in \mathbb{R}^{d_{i+1}\times d_i}, \mathbf{b}_i \in \mathbb{R}^{d_{i+1}}\}$,$\sigma$ 为激活函数。与普通 FC 直接令 $\mathbf{x}_{i+1} = \mathbf{z}_i$ 不同,CAS 不直接输出 $\mathbf{z}_i$,而是把 $\mathbf{z}_i$ 用作"反向信号"去重估 $\mathbf{x}_i$ 的可靠性。
Adaptive Reweighting。用一个逆向的线性层 $g_{\phi_i}: \mathbb{R}^{d_{i+1}} \to \mathbb{R}^{d_i}$ 把 $\mathbf{z}_i$ 映回输入维度,经 Sigmoid 得到逐元素的重要性权重:
$$ \mathbf{e}_i = g_{\phi_i}(\mathbf{z}_i) = \mathrm{Sigmoid}(\mathbf{W}'_i \mathbf{z}_i + \mathbf{b}'_i) \tag{2} $$
其中 $\phi_i = \{\mathbf{W}'_i \in \mathbb{R}^{d_i \times d_{i+1}}, \mathbf{b}'_i \in \mathbb{R}^{d_i}\}$。$\mathbf{e}_i$ 的第 $k$ 维指示原始输入 $\mathbf{x}_i$ 第 $k$ 维的重要性:较小的值对应更强的降噪。然后对输入做乘法式重加权:
$$ \tilde{\mathbf{x}}_i = \mathbf{x}_i \odot 2\mathbf{e}_i \tag{3} $$
这里乘以 2 的设计很关键:Sigmoid 的原始范围为 $(0,1)$,期望是 $0.5$,直接乘会整体压缩激活值,放大梯度消失风险;乘 2 后权重落在 $(0,2)$、期望值为 1,保持激活期望不变的同时允许对噪声维度收缩、对信号维度放大(同 [22])。
Cycle-Forward。用重加权后的 $\tilde{\mathbf{x}}_i$ 与共享参数 $(\mathbf{W}_i, \mathbf{b}_i)$ 再前向一次:
$$ \mathbf{z}'_i = f_{\theta_i}(\tilde{\mathbf{x}}_i) = \sigma(\mathbf{W}_i \tilde{\mathbf{x}}_i + \mathbf{b}_i) \tag{4} $$
$\mathbf{z}'_i$ 原则上可以再作为下一次循环的 $\mathbf{x}_i$ 继续迭代,但作者权衡效果与开销,只用单次循环,令 $\mathbf{x}_{i+1} = \mathbf{z}'_i$。由于 pre-forward 与 cycle-forward 共用同一套 $(\mathbf{W}_i, \mathbf{b}_i)$,CAS 相对原 FC 仅多出 $\mathbf{W}'_i, \mathbf{b}'_i$ 和一次前向,不新增任何特征。
为什么有效。CAS 本质是一种由"当前层已经做出的初步判断 $\mathbf{z}_i$"反过来为"输入 $\mathbf{x}_i$"打一个软性注意力掩码,然后重做一次前向。它是 SENet [10] / Squeeze-and-Excitation 的近亲,但不同之处在于:(i) SENet 作用于通道维;(ii) CAS 作用于每层 FC 输入维,且两次前向共享参数,起到"denoise 并重新积分"的作用。这对于特征维度极高、噪声严重的工业推荐特征尤其重要。
Cross-Tower Synchronization(CTS)¶
动机。双塔在相似度计算前是完全独立的——这是可缓存和 FAISS 友好的关键,但也是对齐的瓶颈。先前工作通过隐式交互(IntTower 的双塔多层交互 [14]、双增强双塔 [29])缓解问题,但没有显式地把对侧塔的表示注入到本侧;而在在线学习下,隐式对齐更不稳定。CTS 提出一个显式且轻量的跨塔信息交换机制。
核心思想。为每个用户 $u$ 和每个物品 $v$ 维护一对跨塔缓存向量 $\mathbf{c}^t_u, \mathbf{c}^t_v$,它们缓存"来自对侧塔的正交互向量",初始化为 $\mathbf{c}^0_u = \mathbf{0}, \mathbf{c}^0_v = \mathbf{0}$。在 $t$ 时刻 $u, v$ 发生交互 $y$ 时,双塔读取对侧上一时刻的缓存作为额外输入:
$$ \begin{aligned} \mathbf{u}^t &= U_{\theta_u}\bigl(\mathbf{x}^t_u,\; \mathbf{c}^{t-1}_u,\; \mathbf{s}^{t-1}_u\bigr), \\ \mathbf{v}^t &= V_{\theta_v}\bigl(\mathbf{x}^t_v,\; \mathbf{c}^{t-1}_v,\; \mathbf{s}^{t-1}_v\bigr), \end{aligned} \tag{5} $$
其中 $\mathbf{x}^t_u, \mathbf{x}^t_v$ 是原始塔特征,$\mathbf{c}^{t-1}_u, \mathbf{c}^{t-1}_v$ 来自 CTS 的前一时刻缓存,$\mathbf{s}^{t-1}_u, \mathbf{s}^{t-1}_v$ 来自 CMS(下一节)。每一轮前向结束后再用本轮的对侧输出 $\mathbf{v}^t$ / $\mathbf{u}^t$ 以 EMA 方式更新缓存:
$$ \mathbf{c}^t_u = \begin{cases} \alpha\, \mathbf{c}^{t-1}_u + (1-\alpha)\, \mathbf{v}^t, & \text{if } y = 1 \\ \mathbf{c}^{t-1}_u, & \text{otherwise} \end{cases} \tag{6a} $$
$$ \mathbf{c}^t_v = \begin{cases} \alpha\, \mathbf{c}^{t-1}_v + (1-\alpha)\, \mathbf{u}^t, & \text{if } y = 1 \\ \mathbf{c}^{t-1}_v, & \text{otherwise} \end{cases} \tag{6b} $$
其中 $\alpha \in [0,1]$ 是平滑系数。注意 CTS 的一个关键设计决策是仅用 $y = 1$ 的正样本更新缓存:作者把 $\mathbf{c}_u$ 视为"用户 $u$ 曾经真实喜欢过的那些物品表示的平滑均值",$\mathbf{c}_v$ 则是"曾真实喜欢过物品 $v$ 的那些用户的表示的平滑均值",都是高度个性化的正向画像。负样本的"不相关"信息不纳入缓存。
为什么 EMA 而非梯度更新。CTS 缓存的更新是 gradient-free 的(与 [13, 24] 的用法类似),主要原因:(i) EMA 天然平滑了对侧的分布漂移,避免在线学习下单步的梯度噪声污染缓存;(ii) 跨塔梯度会让两塔变成端到端耦合,打破双塔架构"可缓存、可并行"的工程优势。因此 CTS 在保留双塔架构骨架的前提下做了显式对齐。
为什么有效。(i) 把对侧表示显式注入本塔输入端,让每一层都能"意识到对方";(ii) 在 online learning 里缓存以实时方式更新,对分布漂移响应更快;(iii) 只更新正样本,让缓存聚焦于"真正相关"的个性化信号。
Cascade-Model Sharing(CMS)¶
动机。召回塔和精排塔之间存在严重的"表达能力断层"——精排可以用交叉特征(CAN [1]、DCN [26, 28])和 target-aware 序列模型(TWIN [5]、Moment&Cross [2]),但双塔召回无法利用这些信号。知识蒸馏可以让召回塔学习一个强 teacher(Ranking Distillation [20, 23]),但它:(i) 仅传递 logit 级别软标签,不解决架构性瓶颈;(ii) 在 online learning 下很难频繁重训 teacher。CMS 的思路更激进:直接把下游 cascade 排序模型的中间输出作为召回塔的额外输入,做特征级复用而非 logit 级蒸馏。
形式。类似 CTS,为每个用户/物品维护 级联向量 $\mathbf{s}^t_u, \mathbf{s}^t_v$,初始化 $\mathbf{s}^0_u = \mathbf{0}, \mathbf{s}^0_v = \mathbf{0}$。在 $t$ 时刻,$\mathbf{s}^{t-1}_u, \mathbf{s}^{t-1}_v$ 与其它特征一起按 Eq. (5) 喂入双塔。设 $\mathbf{h}^t_{uv}$ 是 cascade 排序模型对 pair $(u,v)$ 产出的中间表示(例如最后 FC 层前一层的输出),CMS 用 EMA 更新缓存:
$$ \begin{aligned} \mathbf{s}^t_u &= \beta\, \mathbf{s}^{t-1}_u + (1-\beta)\, \mathbf{h}^t_{uv}, \\ \mathbf{s}^t_v &= \beta\, \mathbf{s}^{t-1}_v + (1-\beta)\, \mathbf{h}^t_{uv}, \end{aligned} \tag{7} $$
其中 $\beta \in [0,1]$ 是平滑系数。与 CTS 不同,CMS 把正样本与负样本产出的 $\mathbf{h}^t_{uv}$ 都视为有用——因为 cascade 模型编码了更丰富的判别知识(正负样本上的对比信号同样重要)。
CMS 与 CTS 的关系是"分层互补":CTS 补齐跨塔间的对齐空洞,CMS 补齐跨阶段的信息空洞。而两者都通过"EMA 缓存 + 输入注入"这一同构机制实现,这使得工程实现代价非常低。
灵活性。CMS 的 cascade 模型可以与双塔联合训练(共享梯度),也可以独立训练在不同样本流上(例如广告场景下的 cascade 用不同采样策略)。后者是 Kuaishou 生产环境的主要选择,见 2.4.3 节。
在线学习实现¶
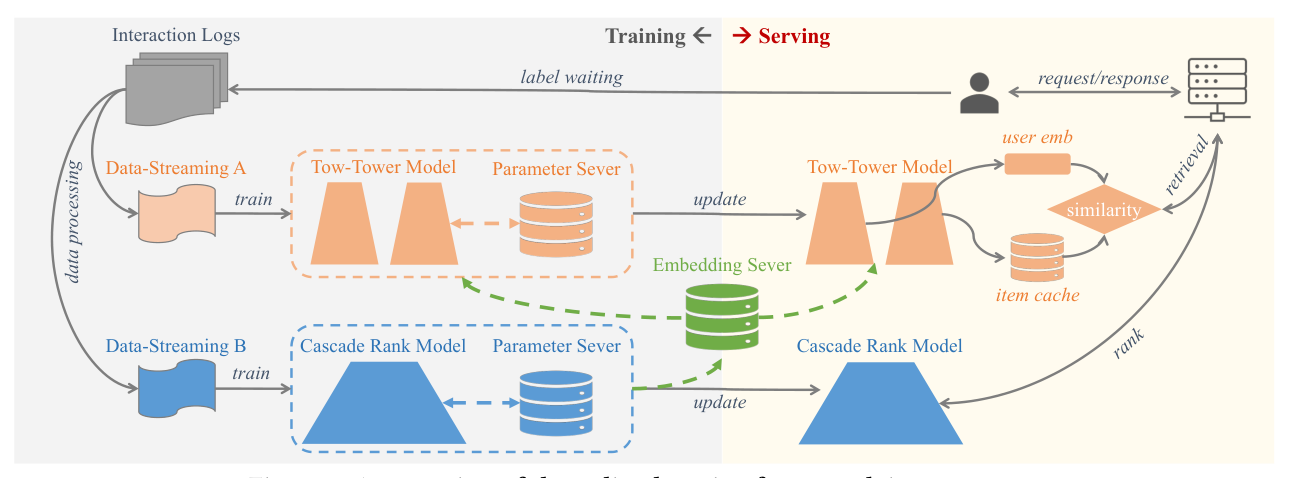
本节讨论 CS3 在一个真实的工业级在线学习系统中的部署架构,是论文把理论落地为工业方案的核心。
2.4.1 在线学习(Online Learning)。在 Kuaishou 的广告系统中,曝光样本经过一段 label waiting period 后产生正/负标签,日志实时摄入训练流,模型参数周期性同步到在线服务端。整个循环通常在一小时内完成,典型周期约 30 分钟。online learning 相比离线训练能显著提升内容新鲜度和用户体验 [2, 16],但它对 CS3 这种"需要跨塔、跨阶段信息交换"的算法提出更严的一致性与延迟约束。
2.4.2 Parameter Server(ParSvr)。生产中使用分布式 Parameter Server 更新和同步模型参数,包括稀疏 embedding(如 per-user_id)。虽然 CTS 的 $\mathbf{c}^t_u, \mathbf{c}^t_v$ 在形态上类似 embedding(都是 user_id / item_id 索引下的稠密向量),但它们不是由梯度更新,而是由 EMA 更新。作者的做法:把 CTS cross vectors 缓存在 ParSvr 中,并通过"自定义梯度"来实现 EMA——即把 $\alpha\,\mathbf{c}^{t-1} + (1-\alpha)\,\mathbf{v}^t$ 的增量包装成一个伪梯度喂给优化器,使其复用现有的参数更新 / 跨节点同步 / 导出机制。这是个工程细节,但关键——它让 CTS 无需引入独立存储系统。
2.4.3 Embedding Server(EmbSvr)。ParSvr 作用域局限于单个训练 job,无法跨 job 共享缓存。当 cascade 模型与双塔独立训练在不同样本流上时(生产常态),CMS 就不能复用 ParSvr。为此作者另起一套独立的 Embedding Server:EmbSvr 是一个分布式 KV 服务,专门存储 embedding,同等硬件下 QPS 更高。Cascade 模型的 $\mathbf{h}^t_{uv}$ 以 user_id / item_id 为 key 写入 EmbSvr 并由 EMA 更新,双塔在训练和服务阶段都从 EmbSvr 读取。这套架构明确地把"跨 job / 跨阶段的缓存"与"job 内的参数"解耦。
2.4.4 效率分析。作者逐模块量化了 CS3 在线服务的开销:
- CTS 和 CMS 只多出两个额外输入向量,计算代价可忽略;CTS 的 cross vector 与其它稀疏特征一起在 ParSvr 更新 / 服务端本地缓存,无可观测延迟影响;CMS 的 cascade vector 从 EmbSvr 取,EmbSvr p99 延迟 <5ms,且访问与其它特征处理并行化,开销可忽略。
- CAS 显著增加每塔的计算量(每层多出一次前向 + 一个 FC),但召回的主要延迟来自大规模相似度搜索(而非塔前向),这部分不受 CAS 影响;且物品 embedding 全部预计算并缓存,只有实时用户塔承担 CAS 的额外开销。
- 作者在 Kuaishou 线上"对除输入层外所有 FC 层应用 CAS"的配置下,只使召回服务 QPS 下降 <1%。
这一节的讲述对工业读者非常重要:CS3 的三个模块不仅数学上合理,而且每一个都匹配到工业中已有的存储和调度基础设施。这是它区别于许多纯算法论文的关键。
实验¶
实验设置¶
离线实验(3 个公开数据集,均同时含用户与物品特征):
- TaobaoAd(tianchi.aliyun.com/dataset/56)
- KuaiRand(kuairand.com)
- RecSys2017(recsyschallenge.com/2017)
骨干双塔架构(4 个):
- DSSM [11]:经典双塔;
- IntTower [14]:隐式双塔交互;
- IHM-DAT [30]:Dual Augmented Two-Tower,双增强;
- RCG [4]:基于 Transformer 的召回模型(来自 "Building a Scalable, Effective, and Steerable Search and Ranking Platform")。
CMS cascade 模型:离线实验中用 4 层 MLP 作为下游排序器,同时建模用户与物品侧特征,与双塔联合训练;代码开源 https://github.com/lixiangwang/CS3Rec 。
评估指标:AUC(越高越好)和 LogLoss(越低越好),5 个随机种子取均值,报告标准差。
在线实验:Kuaishou 广告系统三个业务场景 A/B 测试(共服务数亿用户);CS3 应用在双塔召回阶段,该阶段产生最大候选池,直接影响下游流程的上限。
主要离线结果¶
Table 1 是整篇论文最核心的实验表,展示了 CS3 三个组件及其组合在 4 种双塔 backbone × 3 种数据集上的表现(带 * 表示相对 base 具有 $p < 0.05$ 的显著提升)。
| Model | TaobaoAd AUC↑ | TaobaoAd LogLoss↓ | KuaiRand AUC↑ | KuaiRand LogLoss↓ | RecSys2017 AUC↑ | RecSys2017 LogLoss↓ |
|---|---|---|---|---|---|---|
| DSSM [11] | 0.6194±.0028 | 0.2289±.0002 | 0.6646±.0027 | 0.6763±.0003 | 0.6855±.0073 | 0.6707±.0039 |
| + CAS | 0.6378±.0015 | 0.2271±.0002 | 0.7416±.0004 | 0.5759±.0002 | 0.7093±.0245 | 0.6864±.0129 |
| + CTS | 0.6506±.0018 | 0.2258±.0001 | 0.7095±.0006 | 0.6122±.0004 | 0.7752±.0182 | 0.6166±.0051 |
| + CMS | 0.6632±.0011 | 0.2253±.0001 | 0.7100±.0016 | 0.6094±.0002 | 0.7417±.0130 | 0.6353±.0032 |
| + CS3 | 0.6855±.0005* | 0.2198±.0001* | 0.7484±.0008* | 0.5731±.0004* | 0.8380±.0038* | 0.5308±.0015* |
| IntTower [14] | 0.6507±.0004 | 0.2255±.0001 | 0.7503±.0016 | 0.5782±.0057 | 0.8178±.0057 | 0.6429±.0203 |
| + CAS | 0.6541±.0005 | 0.2251±.0002 | 0.7580±.0052 | 0.5636±.0052 | 0.8511±.0018 | 0.4980±.0015 |
| + CTS | 0.6825±.0088 | 0.2213±.0001 | 0.7527±.0012 | 0.5686±.0005 | 0.8445±.0036 | 0.5975±.0237 |
| + CMS | 0.6745±.0014 | 0.2217±.0005 | 0.7571±.0003 | 0.5787±.0006 | 0.8236±.0062 | 0.6244±.0149 |
| + CS3 | 0.6895±.0003* | 0.2186±.0001* | 0.7615±.0002* | 0.5572±.0002* | 0.8657±.0030* | 0.4888±.0090* |
| IHM-DAT [30] | 0.6302±.0037 | 0.2278±.0001 | 0.7059±.0097 | 0.6387±.0011 | 0.7694±.0031 | 0.6096±.0019 |
| + CAS | 0.6544±.0013 | 0.2247±.0001 | 0.7513±.0024 | 0.6040±.0012 | 0.8529±.0011 | 0.5413±.0017 |
| + CTS | 0.6478±.0017 | 0.2255±.0001 | 0.7083±.0003 | 0.6037±.0006 | 0.7848±.0036 | 0.6044±.0035 |
| + CMS | 0.6532±.0008 | 0.2253±.0001 | 0.7103±.0044 | 0.6022±.0019 | 0.7925±.0021 | 0.6007±.0017 |
| + CS3 | 0.6783±.0012* | 0.2216±.0002* | 0.7556±.0035* | 0.5723±.0005* | 0.8660±.0014* | 0.5307±.0026* |
| RCG [4] | 0.6680±.0001 | 0.2217±.0001 | 0.7814±.0042 | 0.5569±.0028 | 0.7870±.0026 | 0.5697±.0031 |
| + CAS | 0.6741±.0008 | 0.2213±.0001 | 0.8195±.0063 | 0.5361±.0029 | 0.8390±.0027 | 0.5348±.0026 |
| + CTS | 0.6764±.0002 | 0.2210±.0001 | 0.7931±.0025 | 0.5475±.0023 | 0.7954±.0049 | 0.5854±.0041 |
| + CMS | 0.6725±.0009 | 0.2212±.0001 | 0.7906±.0013 | 0.5561±.0010 | 0.8061±.0121 | 0.5689±.0065 |
| + CS3 | 0.6860±.0012* | 0.2203±.0003* | 0.8304±.0009* | 0.5241±.0012* | 0.8676±.0031* | 0.5132±.0073* |
作者从结果中归纳了 6 条重要观察:
- 三模块都有独立贡献:CAS / CTS / CMS 无论在哪个数据集、哪个 backbone 上,相对 base 都能带来提升,验证每个组件的必要性。
- CAS 在 KuaiRand 上增益最大:KuaiRand 的用户 / 物品侧特征最丰富,因此 CAS 的"自修正 + 去噪"机制最能发挥作用。这是对 CAS 机制的一个侧面验证——它确实是对输入特征做 denoising。
- DSSM + CS3 超过 IntTower 和 IHM-DAT 的 base:最经典的 DSSM 在 CS3 加持下可以胜过专门设计的双塔改进方案。这说明 CS3 的增益是结构性的,而非仅仅填补了 backbone 的弱点。
- CTS 在 IHM-DAT 上进一步提升:IHM-DAT 本身已有隐式交叉塔增强,CTS 仍能继续带来增益——验证显式跨塔交换比隐式对齐更有效。这是一条很强的归因结论。
- CMS 在 IntTower 上进一步提升:IntTower 自带塔内交互建模,而 CMS 带来的是跨阶段信号(下游 cascade),因此与 IntTower 原有能力互补。
- CS3 对 Transformer-based RCG 同样有效:说明 CS3 与 backbone 架构正交,具有好的泛化性。
综合看,三模块同时使用(+CS3)在 12 个 (数据集, backbone) 组合上全部取得最佳结果,且 12/12 具有统计显著性。
在线 A/B 测试¶
Kuaishou 广告系统 DAU 超过 4 亿。CS3 首先在 Scenario A 上线,产生 Table 2 的效果:
Table 2: CS3 在 Scenario A 的在线表现
| Method | Revenue | DAC |
|---|---|---|
| BASE | 0.000% | 0.000% |
| + CAS | +1.677% | +0.144% |
| + CAS & CMS | +7.880% | +0.435% |
| + CAS & CMS & CTS (CS3) | +8.356% | +0.468% |
为验证泛化性,作者又在 Scenario B、C 上部署 CS3,报告广告收入(Revenue)、日活客户数(DAC, Daily Active Customers) 和 QPS 变化 三项指标:
Table 3: CS3 在三个场景的在线改进
| Base + CS3 | Scenario A | Scenario B | Scenario C |
|---|---|---|---|
| Revenue | +8.356% | +1.366% | +2.177% |
| DAC | +0.468% | +0.143% | +0.228% |
| QPS | -0.589% | -0.388% | -0.456% |
关键结论:
- 模块增益排序:从 Table 2 的增量看,CAS(+1.677%)→ +CMS(+7.880%,即 CMS 增量约 +6.2%)→ +CTS(+8.356%,即 CTS 增量约 +0.48%)。CMS 是最大贡献者,说明在工业广告场景下,"召回↔精排一致性"是最大的短板;一旦召回能访问精排的中间表示,收益立刻显现。
- DAC 同步提升:广告收入提升并不以牺牲用户体验为代价——DAC(转化相关指标)同步提升,是一个健康的正向指标组合。
- 三场景一致性:Revenue 在三场景分别 +8.36% / +1.37% / +2.18%,虽然幅度差异很大(业务空间不同),但方向完全一致,展示了 CS3 的强泛化性。
- QPS 有轻微下降(每个场景 -0.4% ~ -0.6%),主要来自 CAS 给用户塔增加的前向计算。作者认为相对于效果增益,这个延迟影响可接受。
实验规范性:所有测试都在召回阶段(各场景最大候选源)上用 10% 真实流量、超过 7 天的 A/B 跑出,改进模型再全量替换 BASE。各场景日峰值 QPS >200k。作者明确表示将继续扩展 CS3 到更多模型和场景。
与已归档相关工作的对比¶
(文档库中未发现与 CS3"问题 + 解法"双同构的深读论文。CS3 聚焦判别式双塔召回增强,而当前已归档的深读论文绝大多数位于生成式推荐、长序列建模或精排侧的轴线上,问题同构候选稀少;跳过本章节。)
讨论与局限性¶
核心贡献与借鉴价值。CS3 的最大亮点不是任何单一模块,而是它把"塔内修正 + 跨塔对齐 + 跨阶段复用"抽象成了三种正交的能力交换并统一到一个框架中。对工业推荐读者来说,论文的三个设计可以分开借鉴:
- CAS:一个 Squeeze-and-Excitation 风格的 FC 层替换,对重特征噪声的双塔非常对症,容易迁移。
- CTS:启发在于"对侧表示通过 EMA 缓存而非梯度交互"——这让它在保留双塔可缓存 / 可并行优势的前提下完成显式对齐,是当下轻量跨塔交互的一个值得复用的工程范式。
- CMS:最具启发性的设计。它把"召回↔精排一致性"从传统的 logit-level 蒸馏迁移到了 feature-level 复用,并通过 EMA 把"不同步训练的 cascade 模型"也纳入进来。这为 online learning 下的多阶段一致性问题提供了一条工程化路径。作者在 Parameter Server + Embedding Server 的双存储方案值得借鉴。
生产落地价值。3 个业务场景的 A/B、每场景 >200k QPS、10% 流量 7 天测试、逐步全量替换——这些数据让 CS3 的工业背书远强于大部分学术论文。Scenario A 的 +8.36% Revenue 是非常显著的业务收益。
局限与争议:
- CAS 的"单循环 + 2×Sigmoid"设计未做更严格的消融。作者未展示多次循环是否会进一步带来增益,也未对比"直接 Sigmoid 权重 vs. 2×Sigmoid 权重"的敏感度;对 CAS 的机制选择可做的替代方案(例如 GLU、Gated FC、LayerNorm)也未纳入比较。
- CTS / CMS 的 EMA 系数 $\alpha, \beta$ 未给出调参曲线。这两个系数直接控制跨塔 / 跨阶段信号的"遗忘速度",在 online learning 下对分布漂移的响应速度至关重要;论文仅描述了机制,未报告敏感度分析或作者的推荐值。
- CMS 的 $\mathbf{s}^t_u, \mathbf{s}^t_v$ 更新都用 $\mathbf{h}^t_{uv}$——注意这里一个值得注意的细节:同一个 cascade 输出 $\mathbf{h}^t_{uv}$ 同时写入了用户侧缓存 $\mathbf{s}^t_u$ 和物品侧缓存 $\mathbf{s}^t_v$ 的 EMA。这实际上把 pair-wise 的 cascade 表示"拆开"投射到两个单边缓存中,是否有更优的分离策略(例如用不同的投影头)没有讨论。
- 未比较知识蒸馏基线。与 Ranking Distillation [20, 23] / MSD [16] 等蒸馏方案的直接对比缺失,无法定量回答"CMS 相对蒸馏到底强多少"。
- 论文仅 5 页(SIGIR 短文格式)信息密度极高,但相应的,很多机制选择都没有详细解释或充分消融。这是 venue 限制的自然结果,但对读者而言是一个限制。
公平评价:尽管存在上述未覆盖的实验点,CS3 在工业背书(Kuaishou 广告 4 亿 DAU,三场景一致增益,低延迟可部署)和方法论统一性(三条正交能力轴)两个维度上,都是判别式双塔召回方向 2026 年少见的高质量工业论文。对于需要在严格在线学习延迟预算下增强双塔召回的工程团队,CS3 的三个模块构成一套完整的可落地工具箱。