AMRS:用 Rollout 世界模型做离线偏好优化的情感音乐推荐系统¶
Affective Music Recommendation: A Rollout-Based World Model for Offline Preference Optimization Audrey Chan, Aaron Labbé(LUCID Inc.),Jacob Lavoie, Jordan Bannister, Arsène Fansi Tchango, Guillaume Lajoie, Laurent Charlin(Mila — Québec AI Institute) arXiv:2605.28810v1,2026-05-27
一句话概括¶
AMRS 是 LUCID 健康-健康(health-and-wellness)音乐平台上真实部署的情感音乐推荐系统:它的优化目标不是参与度(engagement),而是听者的情感状态(valence 愉悦度 / arousal 唤醒度);由于服务对象包含痴呆症等神经认知障碍的临床人群,在线实验在伦理上不可行。论文用一个 rollout-based 世界模型(因果 Transformer,同时预测参与度、评分、valence、arousal 四路反馈)当作"离线仿真器",先用行为克隆(Copycat)模仿生产策略,再用 DPO 针对世界模型打分的多目标效用函数做离线偏好优化,KL 惩罚锚定克隆基线以保证安全;同一个世界模型在部署前还充当"压力测试工具"。这是一篇方法论可迁移、且已落地的早期部署验证工作。
1. 研究动机与背景¶
1.1 LUCID 平台与功能性音乐的特殊性¶
LUCID 运营一个横跨两类应用、共享同一套基础设施的健康音乐平台:
- 临床应用(clinical):面向有心理健康和神经认知障碍的人群——主要是老年人,其中很多人患有痴呆症(dementia)或轻度认知障碍(mild cognitive impairment)。
- 消费者健康应用(consumer wellness):面向功能性聆听,分四种模式——energize(提振)、focus(专注)、calm(平静)、sleep(睡眠)。
每个 session 由一个固定的生产策略(production policy)挑选出一串精心编排(curated)的歌曲序列。平台记录三类日志:
- engagement(参与度):歌曲被听完的比例(fraction of a song played),歌曲级(song-level)信号;
- binary like/dislike rating(二元评分):歌曲级信号;
- pre- / post-session 的 valence 与 arousal:在 circumplex(情感环形模型)上的自报情感坐标,session 级(session-level)信号,每个 session 大致只有一对(前后各一次)。
关键点:两类应用的成功指标都不是 engagement,而是听者的情感状态(affective state)。 一首吸引注意力的歌曲未必能产生预期的情感轨迹。为这种场景构建推荐器引入了三个相互交织的约束:
1.2 三大结构性约束(论文的 root cause)¶
约束一:两种性质迥异的反馈信号,且最关键的信号最稀疏。 行为反馈(engagement、rating)在歌曲级观测且相对充足;情感反馈(valence、arousal)只在 session 级观测,大约每个多歌曲 session 一对。尽管 Headspace、Calm、Spotify 歌单这类功能性音乐平台触达数百万听者,但据作者所知,没有一家在可比规模上采集自报情感反馈——这使得最相关的信号恰恰是监督最稀疏的信号。
约束二:在线实验的伦理约束。 当优化目标是情感状态(而非 engagement 的标准 A/B 测试)时,以未经验证的方式去改变 valence 或 arousal 的探索性推荐,对脆弱人群构成真实风险:痴呆患者可能无法跳过歌曲或表达不适,管理压力/焦虑的用户的 arousal 轨迹关乎真实的临床后果。因此离线学习在这里不是数据效率的选择,而是一条伦理约束:策略必须在不让真实听者暴露于未验证的情感干预的前提下完成训练和压力测试。
约束三:生产策略的曝光偏差(exposure bias)。 日志里的歌曲是被固定生产策略选出来的,因此数据反映的是该策略的覆盖范围而非用户的自由选择。该生产策略组合了:基于偏好的检索(genre、基于评分的相似度)、基于规则的播放约束(如 skip 管理)、以及在群体层面(而非个体层面)标注的歌曲级情感标签;它孤立地为每首歌打分,不考虑聆听序列效应,也不考虑任何个体用户已测量的情感反应。如果部署一个未验证的新策略去采集反事实数据来做传统的 off-policy 校正,就会违反伦理约束。
1.3 本文方法¶
论文构建了一个 rollout-based 世界模型(沿用 Ha & Schmidhuber 的 world model 框架,并扩展到行为与情感反馈的联合预测):一个因果 Transformer,在日志聆听数据上训练,给定历史和一个候选下一首歌,预测全部四路反馈信号。这个模型扮演离线 in-silico 仿真器,用来完全离线地训练和压力测试候选策略,并从有限的日志数据集中生成无限的"想象 rollout"。
推荐策略 $\pi_\theta$ 先用行为克隆模仿生产策略,再用 DPO 针对世界模型预测出的(engagement、rating、valence、arousal)所构成的可配置多目标效用函数做微调。DPO 对参考策略的 KL 惩罚充当策略漂移的安全约束。训练完成后,同一个世界模型在任何真实用户暴露之前,用反事实历史对所选策略做压力测试。
1.4 贡献¶
- 一个在严格冷启动(strict cold-start)协议下联合预测行为与情感反馈的 rollout-based 世界模型;
- 一项架构与 embedding 研究:对比标准(standard)与因子化(factorized)因果 Transformer,带/不带位置编码,跨两个基于内容的歌曲 embedding 家族(MERT 与 CLaMP 3);
- 一条离线偏好优化流水线,在尊重多样性约束的同时改进多目标预测反馈;
- 在 LUCID 平台上的部署,配套一个基于世界模型的部署前安全工作流。
论文把自己定位为:在在线实验伦理上不可行时,对情感推荐方法论的一次早期已部署验证。
2. 核心方法 / 模型架构¶
AMRS 由两个组件构成(见 Figure 1):(1) 一个在日志数据上训练的 rollout-based 世界模型,在用户历史的每一步预测四路反馈信号;(2) 一个完全针对世界模型训练的推荐策略——每一步它提议一首下一首歌,世界模型补全(impute)预期反馈,再由此导出一个标量安全分。这种分离带来两个好处:安全性(训练期间无真实用户暴露)和样本效率(一个训练好的世界模型即便在真实交互数据稀缺时也能生成无限模拟 rollout)。
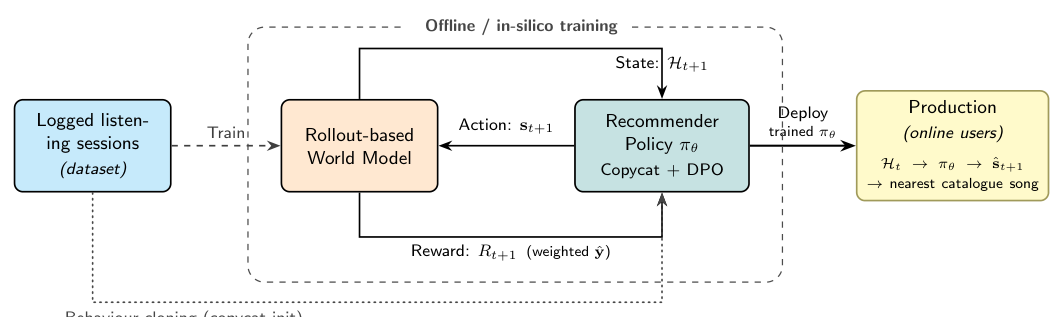
2.1 问题形式化(MDP)¶
将推荐过程建模为马尔可夫决策过程(MDP)。在时刻 $t$,状态是用户的聆听历史 $\mathcal{H}_t$,即一串歌曲交互的序列,每个交互携带四个信号:参与率 $e \in [0,1]$(歌曲被听比例)、二元评分 $r$(可选)、自报 valence $v \in [0,1]$ 和 arousal $a \in [0,1]$(两者在每个多歌曲 session 前后各测量一次,post-session 值可选)。推荐器执行动作 $\mathbf{s}_{t+1}$(下一首歌),世界模型预测:
$$\hat{\mathbf{y}}_{t+1} = (\hat{e}, \hat{r}, \hat{v}, \hat{a})_{t+1} \tag{1}$$
并由此导出一个奖励。状态通过把推荐及其预测反馈追加到历史末尾转移到 $\mathcal{H}_{t+1}$。
2.2 用户历史表示¶
歌曲 embedding:基于内容(content-based),而非 one-hot ID。 之所以用基于内容的 embedding,是为了让系统能在不重新训练的情况下吸收目录新增的歌曲——这对一个目录持续增长的平台是硬需求。论文对比两种策略:MERT(一个自监督声学模型)和 CLaMP 3(一个多模态音乐-语言模型)。没有采用 one-hot identity 编码:它无法泛化到新目录项,且在 pilot 实验中表现明显逊于两种基于内容的方案。
历史 token 序列: 历史被表示为 token 序列,每个 token 拼接了——歌曲 embedding、可用的反馈信号、以及指示该 token 哪些信号存在的二元掩码(binary masks)。这种统一表示天然处理缺失数据(valence/arousal 只在 session 边界 token 上存在;rating 在任意步都可能缺失),并支持向模型查询任何带歌曲的 token 上的任意信号。穿插其间的 "session-boundary"(session 边界)token 分隔不同聆听 session,并携带不绑定到任何单首歌的 pre-session valence/arousal 报告。
2.3 世界模型¶
世界模型是一个因果 decoder-only Transformer。论文对比两个变体——一个标准(standard)Transformer,把反馈右移(right-shift)以保持因果性;一个因子化(factorized)Transformer,把历史编码与反馈预测分离——并只详细描述实际部署的因子化变体。
因子化 Transformer: 在用户历史前面加一个可学习的 Begin-Of-Sequence(BOS)token,因果 Transformer 产出一串用户历史 embedding $\mathbf{z}_i$,每个编码截至位置 $i$(含)的用户历史。给定一个候选下一首歌的 embedding $\mathbf{s}_{t+1}$,一个轻量 MLP 预测头作用在拼接 $[\mathbf{z}_i; \mathbf{s}_{t+1}]$ 上,输出四维预测反馈。当使用位置信息时(Table 2 中的 "+PE" 行),在 Transformer 层之前施加旋转位置编码(rotary positional encodings, RoPE);no-PE 配置除了 BOS token 和因果掩码外不使用任何显式位置信号。
这种因子化带来三个实际优势: 1. 可解释性:提供一个专门的历史 embedding,被 §4.4 的消融使用; 2. 整个目录的并行打分:历史只需一次前向,候选歌曲通过预测头轻量打分(catalogue-scale 上更便宜); 3. 歌曲与其反馈在输入序列中天然配对,免去标准 Transformer 为保持因果性所需的右移操作。
训练: 两个架构都用复合损失训练——连续信号(engagement、valence、arousal)用 MSE,二元 rating 目标用 BCE,且仅在对应目标被观测到的位置计损失。pre-session valence 与 arousal 作为输入信号进入、不贡献损失;只有 post-session 值是预测目标。训练采用 Monte Carlo Cross-Validation(MCCV),做 10 个随机 80/10/10 划分,按 user ID 划分,因此验证和测试用户在训练期间严格不可见——这就是 Marlin & Zemel 的 "strong generalization"(强泛化)协议。同样的 10 个划分被复用于所有被比较的世界模型变体,使各配置之间能做配对比较。按信号分别保存验证 loss 最优的 checkpoint,评估时加载每路信号各自最佳的 checkpoint。为了让训练期间见到多样的序列上下文,每个 epoch 对每个用户重采样 5 个窗口,每个窗口长度从 $[50, 1000]$ token 中随机抽取、起点随机;验证和测试使用每个用户的完整历史。
2.4 推荐策略¶
推荐策略 $\pi_\theta$ 同样是一个因果 decoder-only Transformer,把历史 $\mathcal{H}_t$ 映射到下一首歌的 embedding 预测 $\hat{\mathbf{s}}_{t+1}$,再通过余弦相似度匹配到目录里得到最终推荐。
Copycat 初始化(行为克隆)。 先训练一个 Copycat 模型,通过行为克隆模仿生产策略:给定 $\mathcal{H}_t$,模型预测实际播放的下一首歌的 embedding,训练用 InfoNCE 对比损失:
$$\mathcal{L}_{\text{Copy}} = -\mathbb{E}\left[\log \frac{e^{\text{sim}(\hat{\mathbf{s}}, \mathbf{s}^+)/\tau}}{e^{\text{sim}(\hat{\mathbf{s}}, \mathbf{s}^+)/\tau} + \sum_{\mathbf{s}^- \in N_t} e^{\text{sim}(\hat{\mathbf{s}}, \mathbf{s}^-)/\tau}}\right] \tag{2}$$
其中 $\hat{\mathbf{s}} = f(\mathcal{H}_t)$,$\mathbf{s}^+$ 是真实的下一首歌,$N_t$ 是一组未播放歌曲的 embedding,sim 是余弦相似度,$\tau$ 是温度。由于生产策略组合了基于偏好的检索、基于规则的播放约束和全局歌曲级情感标签,且孤立地对每首歌操作(而非在序列上操作),这些标签在群体层面而非针对个体测量反应去靶向情感,因此 Copycat 模仿继承了它基于标签的行为先验——DPO 可以在此之上通过基于实测反馈的优化加以改进。
Direct Preference Optimization(DPO)。 从 Copycat 参考 $\pi_{\text{ref}}$ 出发,用 DPO 微调。对每个状态 $x = \mathcal{H}_t$,构造偏好对 $(y_w, y_l)$,其中 $y_w$ 在世界模型下有更高的预测效用分(更被偏好的歌),$y_l$ 是更不被偏好的歌:
$$\mathcal{L}_{\text{DPO}} = -\mathbb{E}_{(x, y_w, y_l)}\left[\log \sigma\left(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)}\right)\right] \tag{3}$$
其中 $\beta$ 控制对参考策略的 KL 惩罚强度。这个 KL 项是把"已被临床验证过行为的生产策略"当作锚,防止策略过度漂移——既是优化项,也是安全约束。
偏好对构造(negative history sampling)。 对每一个生产推荐收到负反馈的时间步,识别一个在世界模型下很可能收到正反馈的目录替换品。大小为 $M$ 的候选池组合了两类采样:
- 纠错采样(corrective sampling):在 embedding 空间中取被差评歌曲的 top-$M/2$ 最近邻;
- 探索采样(exploratory sampling):从目录其余部分均匀抽 $M/2$ 个。
效用分最高的候选成为 $y_w$;原来被差评的推荐成为 $y_l$。这种构造显式地是反事实的:它瞄准生产策略犯的错误,并提出由世界模型打分的修正方案。
Rollout 播种(window strategy)。 推荐器的训练和评估采用窗口策略:每个 rollout 的初始历史 $\mathcal{H}_0$ 是用户日志序列的一个连续片段(一个 window),每个用户 5 个窗口,每个长度从 $[10, 100]$ token 随机抽取、起点随机。这把有效训练信号放大约 5 倍,给每个用户历史更密的覆盖;它迫使策略在部分历史(partial histories)上行动,既匹配强泛化协议评估的冷启动情形,也匹配部署时预期的部分历史条件。训练、微调、评估用同一批窗口,使跨策略比较可复现。
多 seed 训练与评估。 被比较的四个策略(Copycat、DPO,以及 §4.5 定义的 Random/Greedy 基线)都用 $N=5$ 个随机 seed 跑,seed 在各策略间共享,使跨策略比较是配对的。报告的指标是跨 seed 均值 ± 标准差(SD)。
2.5 多目标效用函数与安全约束¶
效用函数把每一步的预测反馈映射为一个标量效用 $R_t$(即 RL 框架中的奖励),是四个预测信号的加权组合:
$$R_t = \lambda_r \hat{r}_t + \lambda_e \hat{e}_t + \lambda_v \hat{v}_t + \lambda_a \hat{a}_t, \quad \lambda_\bullet \in [-1, 1] \tag{4}$$
DPO 在这个每步效用上对偏好对打分(§2.4);评估时报告每路信号的 rollout 平均 $\frac{1}{L}\sum_t \hat{y}_t$,它们共同组成这个效用。具体权重在 DPO 微调时设定,取决于部署的产品或临床目标。本文实验使用 affect-only(仅情感)权重。
AMRS 的安全性通过三个机制编码,每个对应一个具体的伦理关切:
- 完全离线训练与压力测试:所有策略学习都在世界模型中进行;同一模型在训练后也用于在任何真实用户暴露前用反事实历史探测策略(§5.1);
- 通过 Copycat 与 KL 做曝光偏差校正:日志反映的是生产策略的覆盖而非自由选择;通过克隆生产策略并在 DPO 中对其施加 KL 惩罚来锚定新策略,并由显式的策略一致性评估监控(§4.6);
- 分布鲁棒性:联合追踪多样性指标(coverage、normalized entropy、ILD、Gini)与预测反馈,以检测推荐坍缩(recommendation collapse)。
3. 实验设置¶
评估沿三个轴展开:预测反馈质量(四路信号的 rollout 表现)、分布鲁棒性(coverage、entropy、ILD、Gini)、策略一致性(对日志生产策略的 adherence)。
3.1 数据集(Table 1)¶
实验使用 LUCID 已部署平台的专有数据集,汇集临床和消费者健康两个应用的日志。每个聆听 session 是固定生产策略选出的精编歌曲序列,因此观测序列反映的是该策略的覆盖。诸如"播放 vs 未播放"的隐式信号是不完美的偏好代理(offline 推荐评估的普遍 caveat),在这里尤其重要,因为 DPO 的候选替换步骤依赖于日志交互。
| 统计量 | 计数 |
|---|---|
| 唯一用户数 | 939 |
| 唯一 session 数 | 8,784 |
| 用户-歌曲交互数 | 57,822 |
| 唯一播放歌曲数 | 5,992 |
| 歌曲目录规模 | 6,988 |
| 正评分数 | 16,927 |
| 负评分数 | 2,561 |
| Pre-session valence/arousal | 8,784 |
| Post-session valence/arousal | 5,319 |
数据按 user ID 用 MCCV 做 80/10/10、10 个随机划分,因此单个用户的所有交互都落在同一个划分内(强泛化 / 冷启动评估)。注意数据规模相当小(千级用户、万级交互),这也是论文反复强调"冷启动""稀疏监督""数据效率"的现实背景。
3.2 评估指标¶
世界模型指标。 对连续信号(engagement、valence、arousal)报告 $R^2$(相对于均值预测器所解释的方差比例;负值表示比均值预测还差)。对二元 rating 信号报告 ROC AUC,只在实际观测到 rating 的 token 上计算。
推荐器指标。 预测反馈质量通过世界模型下的 rollout 评估:每个 seed,推荐器生成 $L=5$ 首歌,报告平均预测 engagement、rating、valence、arousal。多样性用四个互补指标:
- coverage:跨 rollout 至少出现一次的目录项比例;
- normalized entropy:推荐分布的熵除以目录均值;
- ILD(intra-list diversity):一个 rollout 内内容 embedding 的平均成对余弦距离,按目录均值归一化;
- Gini 系数:item 出现分布的不平等度。
一个坍缩的策略表现为:coverage 和 entropy 近零、ILD 近零、Gini 近 1——这正是贪心优化产生的模式(见 Table 4)。
策略一致性指标。 在三个严格级别上评估对生产策略的 adherence,报告 Hit@10、MRR、NDCG@10、(仅 Level 3)accuracy。这是诊断量,不是优化目标:一个完美模仿生产策略的策略无法改进它,而论文用 DPO 来展示对克隆基线的受控漂移。
- Level 2(用户历史模仿):item 出现在该用户日志历史的任何位置就算相关(主分析级别);
- Level 3(时间步模仿):item 只有匹配对应时间步的确切歌曲才算相关(一个无任何学习策略能在冷启动下达到的严格上界);
- Level 1(目录曝光) 也被考虑过,但被排除——因为基于曝光定义的相关性会被生产策略采样偏差人为抬高。
4. 主要实验结果¶
4.1 世界模型结果(Table 2)¶
Table 2 跨架构和 embedding 配置报告世界模型结果,把歌曲级行为信号(engagement、rating)与 session 级情感信号(valence、arousal)分开。阴影行是按各信号等权平均排名选出的配置(连续目标用 MSE、二元 rating 用 AUC 作主指标)。加粗 = 各指标最优均值;星号 = 与阴影行的配对 t 检验($^*p<0.05$,$^{**}p<0.01$,$^{***}p<0.001$)。
| Arch. | Config | Eng. MSE↓ | Eng. R²↑(%) | Rating AUC↑(%) | Val. MSE↓ | Val. R²↑(%) | Aro. MSE↓ | Aro. R²↑(%) |
|---|---|---|---|---|---|---|---|---|
| Transformer | CLaMP 3 | 0.059 | 10.3* | 68.8** | 0.029** | 36.7** | 0.040 | 32.5 |
| Transformer | MERT | 0.055 | 16.9 | 72.9* | 0.026 | 43.3 | 0.036 | 40.2 |
| Transformer | CLaMP 3 + PE | 0.058 | 12.0* | 64.3*** | 0.031 | 31.6 | 0.038 | 35.9 |
| Transformer | MERT + PE | 0.057 | 13.6 | 67.7** | 0.031*** | 33.6*** | 0.038 | 35.7 |
| Factorized | CLaMP 3 | 0.056 | 15.6 | 71.7 | 0.029 | 39.0 | 0.036 | 39.6 |
| Factorized | MERT(阴影/部署) | 0.055 | 16.4 | 74.1 | 0.027 | 42.6 | 0.037 | 37.9 |
| Factorized | CLaMP 3 + PE | 0.057 | 14.2 | 73.1 | 0.030** | 36.3** | 0.039 | 35.1 |
| Factorized | MERT + PE | 0.055 | 16.3 | 73.4 | 0.029 | 37.4* | 0.039 | 34.5 |
(均值,括号内 SD 见原文;上表为便于阅读省略 SD。SD 量级:engagement R² ~5–10、valence/arousal R² ~10–20。)
论文强调三个值得关注、且预期能泛化到具体世界模型实例之外的模式:
(i) MERT 不带位置编码是跨信号最鲁棒的配置。 因子化 MERT(no-PE)行按跨信号平均排名总体最优,在每个单项指标上都接近榜首。Transformer MERT(no-PE)变体在 engagement 和情感信号的单指标峰值上与之匹配。选择因子化变体部署,是因为它产出被消融和推荐器使用的专用历史 embedding,且其并行打分路径在 catalogue 规模上计算更便宜。No-PE 配置普遍匹配或优于其 +PE 对应物,在 MERT embedding 下效果最强——这暗示因子化模型的 BOS token 和因果掩码已经隐式编码了序列位置,使显式位置编码冗余、甚至在若干情况下略有害。
(ii) MERT 在多数信号上优于 CLaMP 3。 固定架构和 PE,MERT 在 engagement、rating、valence 上每个配置都匹配或优于 CLaMP 3。在 arousal 上结论混合:CLaMP 3 在因子化配置和 Transformer + PE 下有小优势,MERT 只在 Transformer no-PE 下胜出。MERT 的声学表示对逐 token 反馈预测是更有用的先验,尽管 CLaMP 3 是为更高层音乐语义设计的;微调或任务对齐的 embedding 是未来方向。
(iii) Session 级情感在严格冷启动下是可预测的。 在各自最优配置下 valence $R^2$ 达 43.3%、arousal $R^2$ 达 40.2%,部署的因子化 MERT 行为 42.6% / 37.9%。考虑到验证/测试用户严格不可见、session 级标签比歌曲级交互稀疏一个数量级,这个结果相当可观。音乐情感识别(MER)的 benchmark 跨度很大:在 DEAM、PMEmo、EmoMusic 等数据集上(每个片段携带单一共识标签),valence 报告 $R^2$ 约 50–65%、arousal 约 60–80%。本文的 42.6% / 37.9% 低于这个范围,但任务更难:严格冷启动、按 session 的听者特异情感(而非按刺激的共识),这是已知会降低性能的设定。推荐器依赖于按预测情感对候选歌曲排序而非绝对校准,这些 $R^2$ 值足以支撑这一点。
4.2 消融实验(Table 3)¶
Table 3 在选定的因子化 MERT(no-PE)配置上做 leave-one-feature-out 消融,每次在训练和测试中同时移除一个输入组件。
| Configuration | Eng. MSE↓ | Eng. R²↑(%) | Rating AUC↑(%) | Val. MSE↓ | Val. R²↑(%) | Aro. MSE↓ | Aro. R²↑(%) |
|---|---|---|---|---|---|---|---|
| Factorized MERT no-PE(base) | 0.055 | 16.4 | 74.1 | 0.027 | 42.6 | 0.037 | 37.9 |
| − User history | 0.067*** | −1.4*** | 56.9*** | 0.045*** | 4.2*** | 0.057*** | 4.6*** |
| − Feedback signals | 0.062** | 5.4*** | 59.3*** | 0.045*** | 3.2*** | 0.061*** | −0.5*** |
| − Historical songs | 0.054 | 18.1 | 74.0 | 0.026 | 44.1 | 0.035 | 41.2 |
| − Max lookback 10 | 0.053 | 17.9 | 73.5 | 0.025 | 45.8 | 0.034 | 42.7 |
| − Max lookback 5 | 0.054 | 16.9 | 73.5 | 0.028 | 39.0 | 0.036 | 38.9 |
| − Recommended song | 0.055 | 16.2 | 73.4 | 0.028 | 40.0 | 0.037 | 37.9 |
分析: 移除用户历史或过去的反馈信号会显著降级每一路信号(所有情况 $p<0.01$ 起,多数 $p<0.001$)——例如移除用户历史后 engagement $R^2$ 从 16.4% 崩到 −1.4%、valence $R^2$ 从 42.6% 崩到 4.2%、arousal 从 37.9% 崩到 4.6%;移除反馈信号后 arousal $R^2$ 甚至变负(−0.5%)。这说明历史与过去反馈共同承载了在此数据规模下的主导预测信号。其余消融都在噪声范围内。Max-lookback 10(只回看最近 10 步)是按平均排名最好的消融,在 session 级情感上有最大名义增益(valence $R^2$ 45.8%、arousal 42.7%),暗示近期上下文捕获了大部分预测价值。移除历史歌曲(但保留反馈和 session 边界 token)在各信号上有小幅增益;移除推荐歌曲在各信号上有小幅下降。综合看:用户行为信号(engagement、rating、valence/arousal)承载主导预测权重,歌曲内容 embedding 起次要作用,且这一作用大多集中在最近的历史里。由于这些波动都落在噪声内,base 配置被保留为部署配置。
世界模型的中心性(centrality): 两个会"坍缩"的消融(−用户历史、−反馈信号)识别出世界模型产出有用预测所必须拥有的输入(input sufficiency,输入充分性)。当世界模型不具信息量时,每个下游组件——DPO 偏好打分、式 (4) 的 rollout 效用函数、§5.1 的压力测试——都失去信号。因此消融支持把 rollout 世界模型定位为 AMRS 的中心组件而非辅助组件。
4.3 推荐器结果(Table 4)¶
推荐器结果来自同一个世界模型下的 rollout 仿真(也是用来构造 DPO 偏好对的那个)。论文坦诚一个重要 caveat:由于 DPO 既针对该模型优化又针对它评估,增益可能部分反映"仿真器利用(simulator exploitation)"而非真实用户结果改善;预测可能回归到训练数据均值,且复合误差可能扭曲长 horizon 估计。与只依赖输入充分性的消融发现不同,下面的推荐器结果条件于这个特定的世界模型。
优化目标: DPO 策略在 affect-only 效用($\lambda_v = \lambda_a = 0.5$,$\lambda_e = \lambda_r = 0$)上微调——valence 和 arousal 是优化目标,rating 和 engagement 被排除在目标外作为无降级检查(no-degradation check),预期在它们上有小幅下降是可接受的,为未来的效用权重留出余量。
四个对比策略: Random(从目录均匀采样,覆盖广、反馈均值回归,下界);Greedy(在世界模型下给每个候选打分并选预测反馈最高者,严重分布坍缩,退化的上界);Copycat(行为克隆模仿生产策略);DPO(Copycat 在上述 affect-only 效用上微调)。
Table 4(window 策略,test split,$L=5$ 首,$N=5$ seed;rating 和 engagement 不在 DPO 目标内;跨 seed 均值(SD);加粗 = 学习策略 Copycat/DPO 中更优者;星号 = 对 DPO 的配对 t 检验):
| Model | Valence↑ | Arousal↑ | Rating↑ | Engagement↑ | Cov.↑ | Norm.Ent.↑ | ILD↑ | Gini↓ |
|---|---|---|---|---|---|---|---|---|
| Copycat | 0.480*** | 0.433*** | 0.866*** | 0.765*** | 0.029*** | 0.450*** | 2.166*** | 0.993* |
| DPO | 0.499 | 0.449 | 0.830 | 0.725 | 0.022 | 0.478 | 1.763 | 0.993 |
| Baselines: | ||||||||
| Random | 0.202*** | 0.171*** | 0.876** | 0.643*** | 0.287*** | 0.853*** | 0.997*** | 0.750*** |
| Greedy | 0.610*** | 0.550*** | 0.782*** | 0.572*** | 0.002*** | 0.221*** | 0.480*** | 0.999*** |
分析: 结果与离线偏好优化的故事吻合。在 DPO 目标上,valence 和 arousal 相对 Copycat 改进 4.0% 和 3.7%(都 $p<0.001$,配对跨 seed),差距分别约为每策略 seed-SD 的 2× 和 1.5×。在被排除的歌曲级信号上(Table 4 中间一对),rating 和 engagement 下降 4.2% 和 5.2%,与情感改进大致同量级;这些小幅下降表明 DPO 没有为优化情感而牺牲歌曲级信号(与 Greedy 不同),为未来 $\lambda_e, \lambda_r > 0$ 的效用权重留出了余量。
DPO 的多样性 profile 相对 Copycat 有适度偏移,四个偏移都统计显著($p<0.05$ 起,配对跨 seed):coverage 和 ILD 下降(0.029→0.022,2.17→1.76),而 normalized entropy 上升(0.450→0.478),Gini 不变。这说明 DPO 聚焦于更小的目录切片,但在该切片内比 Copycat 分布得更均匀。DPO 远离了 Greedy 表现出的分布坍缩(coverage 0.002、ILD 0.480)。在基线中,Greedy 以近零覆盖和表中最低 ILD 为代价最大化预测情感;Random 覆盖最广但预测情感最低,反映了世界模型对未见过的"歌曲-历史"组合的均值回归预测。论文再次提醒:DPO 相对 Copycat 的情感增益的绝对量级条件于打分用的世界模型。
4.4 策略一致性(Table 5)¶
Table 5 报告 window 策略下的用户级(Level 2)和时间步级(Level 3)对生产策略的 adherence。adherence 是诊断量、非目标:完美模仿无法改进,所以预期 Copycat 主导,DPO 展示受控漂移。
| Split | Metric | Copycat | DPO | Random | Greedy |
|---|---|---|---|---|---|
| Level 2 (user-wise) | |||||
| Train | Hit@10 | 0.937 | 0.674 | 0.039 | 0.163 |
| Train | MRR | 0.732 | 0.393 | 0.015 | 0.052 |
| Train | NDCG@10 | 0.359 | 0.179 | 0.018 | 0.062 |
| Val | Hit@10 | 0.266 | 0.092 | 0.037 | 0.100 |
| Val | MRR | 0.114 | 0.041 | 0.013 | 0.029 |
| Val | NDCG@10 | 0.123 | 0.043 | 0.017 | 0.043 |
| Test | Hit@10 | 0.279 | 0.186 | 0.036 | 0.084 |
| Test | MRR | 0.121 | 0.089 | 0.012 | 0.038 |
| Test | NDCG@10 | 0.130 | 0.089 | 0.016 | 0.048 |
| Level 3 (time-step, test) | |||||
| Test | Accuracy | 0.005 | 0.003 | 0.000 | 0.000 |
| Test | Hit@10 | 0.033 | 0.016 | 0.002 | 0.002 |
| Test | MRR | 0.012 | 0.006 | 0.000 | 0.001 |
| Test | NDCG@10 | 0.015 | 0.007 | 0.001 | 0.001 |
(跨 seed 均值;Level 3 SD ≤ 0.005,Level 2 train/test SD ≤ 0.05、validation ≤ 0.08。)
分析: 在 Level 2,Copycat 主导训练 split(Hit@10 = 0.94、MRR = 0.73),确认行为克隆成功;在未见的验证/测试用户上急剧下降(test Hit@10 = 0.28),这正是强泛化协议下预期的冷启动行为。DPO 在每个 split 都低于 Copycat 但远高于 Random 和 Greedy:对克隆参考的 KL 惩罚产生了朝情感目标的受控漂移,而非对生产策略的完全替换。在 Level 3,每个学习策略在 test split 上的 Hit@10 都远低于 4%,确认严格的时间步匹配在冷启动下不是可达目标,Level 2 才是实质比较的恰当级别。Greedy 在 Level 2 的非零数值反映的是它集中于一小撮出现在许多用户历史中的热门歌曲,而非真正的模仿。每个策略间隔(Copy-DPO ≈ 0.09、DPO-Greedy ≈ 0.10、DPO-Random ≈ 0.15,Hit@10 上)超过最差跨 seed SD(≤ 0.05)约 2 倍以上,所以排序对 seed 变动鲁棒。
5. 讨论与部署¶
5.1 世界模型作为压力测试工具¶
训练好的世界模型在部署前还能压力测试候选策略。通过在合成或扰动的历史上做条件(atypical 的 pre-session valence/arousal、冷启动用户),能暴露不良行为,例如覆盖坍缩和大幅 arousal 摆动;这些可以转化为部署时的护栏(deployment-time guardrails),例如每步最大 arousal 增量(maximum per-step arousal delta)、最小覆盖下限(minimum coverage floor),在任何真实用户暴露之前生效。这是同一个世界模型的"第二重身份":既是离线仿真器,又是部署前安全闸。
5.2 局限性与泛化¶
数据集是单平台、单一生产策略下采集的,因此跨平台验证留作未来工作。DPO 增益的绝对量级和各指标的最优配置也特定于这个训练好的世界模型和数据集。但上面报告的定性模式——Greedy 坍缩、DPO 以受控方式漂移于 Copycat、消融的输入充分性条件——是架构性的,与离线 RL 文献一致,是更可迁移的结论。(数据规模仅约千级用户、5.7 万交互,这是所有"绝对量级仅作参考"提醒的现实根源。)
5.3 伦理考量¶
在这种设定下,仅离线训练是一条伦理律令:部署未经测试、会影响情感状态的策略等于不受控的人体实验,而临床用户可能只有有限的能力表达不满。论文采用的保障(训练期无真实用户暴露、Copycat 锚定、KL 惩罚的 DPO、多样性与策略一致性监控)是必要但不充分的:临床监督下的在线评估仍是最终验证步骤。
5.4 未来工作¶
- 推荐器侧:探索不同效用权重,包括基于用户自述意图(energize vs. calm)的动态切换;把 DPO 从单步对扩展到多歌曲子序列以服务序列性治疗结构(如朝睡眠的 arousal-reduction 轨迹);为生产约束(重复限制、覆盖下限)加一个轻量 re-ranker。
- 世界模型侧:更丰富的用户上下文(概率模型、任务对齐 embedding、time-of-day、生物信号、更强的声学/语义 embedding、更长上下文窗口),以及随着新日志积累的持续重训练以让仿真器与平台漂移对齐。
- 最后,临床监督下精心限定范围的在线评估是剩下的验证步骤。
6. 核心贡献总结¶
- rollout-based 世界模型:一个因果 Transformer,在严格冷启动协议下联合预测行为(engagement、rating)与情感(valence、arousal)反馈;据作者所知,是首个把 session 级情感自报作为优化目标纳入推荐世界模型的工作。消融证明它是系统的中心组件而非辅助件。
- 架构 + embedding 研究:标准 vs 因子化 Transformer、带/不带 RoPE、MERT vs CLaMP 3 的系统对比;结论是因子化 + MERT + no-PE 最鲁棒且部署最经济。
- 离线偏好优化流水线:Copycat 行为克隆 + 基于世界模型打分的 negative-history-sampling 偏好对 + DPO,在改进多目标预测反馈的同时避免分布坍缩、尊重多样性约束。
- 可落地的安全工作流:完全离线训练、Copycat+KL 锚定校正曝光偏差、世界模型部署前压力测试转化为护栏——把"伦理上不可在线实验"这一硬约束转化为一套可操作的工程方法论,并已在 LUCID 平台部署。
7. 讨论与局限性(评注)¶
值得借鉴的设计。 这篇论文最大的价值不在某个单点技术新颖性(世界模型、DPO、行为克隆都是已有积木),而在于把"伦理约束 + 稀疏情感监督 + 曝光偏差"这一现实困境,干净地翻译成一套自洽的离线方法论,并且每一个组件都精确对应一个约束:world model ↔ 无在线实验、Copycat+KL ↔ 曝光偏差与安全锚定、多样性监控 ↔ 坍缩检测、压力测试 ↔ 部署前护栏。这种"约束驱动的架构"叙事,对任何优化目标本身具有伦理/安全敏感性的推荐场景(医疗、心理健康、儿童、金融建议)都有方法论迁移价值。把世界模型同时当"训练仿真器"和"部署前压力测试器"的双重用途,也是一个轻量却实用的安全工程范式。
核心局限/争议。 (1) 评估的循环性:推荐器的全部增益都在用来训练它的同一个世界模型里测量——论文非常坦诚地把这称作可能的"simulator exploitation",并明确指出 valence/arousal 的 4.0%/3.7% 增益的绝对量级"条件于该世界模型"。没有任何真实用户结果(哪怕一次小规模在线读数)来锚定这些离线增益,所以严格说目前是"模型自洽"而非"用户验证"。(2) 数据规模极小:939 用户、5.7 万交互、5,319 个 post-session 情感标签——在这个规模下,世界模型的 valence/arousal $R^2$(约 40%)虽然相对均值预测器显著,但离可用于绝对校准还有距离;论文用"只需排序不需校准"来辩护,但 DPO 偏好对的质量直接依赖于这些预测的排序正确性,循环依赖再次出现。(3) affect-only 实验权重:尽管效用函数设计为多目标可配置,本文只实测了 $\lambda_e=\lambda_r=0$ 的纯情感权重;多目标 trade-off 的真实 Pareto 前沿尚未展示。
与已有工作的差异。 相比 RecSim / KuaiSim / Spotify 歌单生成等只建模行为信号的推荐世界模型,AMRS 的差异是把 session 级情感自报纳入联合预测目标;相比把离线 RL/DPO 当作"数据效率或工程便利"的主流动机,本文把离线学习提升为伦理约束;相比最接近的 Moodify(在 40 名健康成人实验室数据上做 Q-learning),AMRS 是在真实部署日志上完全离线训练、显式校正曝光偏差、并支持可扩展到情感之外的多目标效用。由于 Moodify 未公开,无法做 head-to-head 基准——这也是本文未提供与外部方法直接对比的客观原因。
总评。 一篇工程与伦理叙事都很扎实、但实证闭环尚未完成的部署论文。它的贡献是"方法论 + 早期部署",而非"被验证的用户收益"。对关注 RecSys 安全落地、离线偏好优化、情感计算交叉领域的读者,是一个高质量的范式样本;但若期待硬核的离线/在线一致性证据或大规模数据上的 SOTA 数字,则会落空——而论文自己也从未做此承诺。