研究动机与背景¶
生成式信息检索 (Generative Information Retrieval, GenIR) 把传统"先建倒排索引、再用 query 触发匹配"的检索流程,重塑成一个端到端的自回归生成任务:模型直接接收一个自然语言 query $q$,自回归地生成对应文档标识符 (docid) $I_d=(t_1,\ldots,t_{|I_d|})$。这种 "model-as-index" 范式带来了三个直接好处:(i) 把 retrieval 和索引压缩进同一组参数,省去了独立维护的索引结构;(ii) 把检索决策完全编译进 Transformer 权重,可以无缝复用预训练 LM 的语义先验;(iii) 推理阶段只需用一颗预先构造好的 prefix trie $\mathcal{T}(\mathcal{D})$ 做 constrained decoding,就能保证生成的 token 序列一定落在合法 docid 集合内。
然而在真实的检索语料里,文档集合是高度动态的:新闻、商品、网页都在持续涌入,检索系统必须在不损害历史性能的前提下"边吸收新知识、边维持旧能力"。这一需求暴露了 GenIR 模式上的根本短板:
- 模块化检索系统(BM25 / dense retriever)之所以容易扩展到动态语料,是因为索引(倒排表 / 文档 embedding)独立于查询编码器,可以单独追加;
- GenIR 把 query→docid 的全部映射固化在网络参数里,新增文档要么需要昂贵的全量重训(rehearsal),要么需要在原模型上做参数高效微调(LoRA、Adapter、Prompt Tuning 等)。后者看似优雅,却普遍引发 catastrophic forgetting:随着会话推进,新切片性能上升,但旧切片 (legacy slice) 的检索质量被持续侵蚀。
作者把这一对立形式化为 plasticity–stability trade-off:当下学到的新映射(plasticity)会与历史映射(stability)在同一组权重里相互干扰。本文先用大量受控实验把"干扰来源"逐一拆解,然后提出 Post-Adaptation Memory Tuning (PAMT) 框架,以一个旁挂的 parametric memory head (PMH) 为载体,在不改动主干、不重放旧监督的前提下,把"灾难性遗忘"压低到接近索引型基线的水平。
核心贡献总结: 1. 用两类 docid 设计(语义 product-quantized SPQ vs. 关键词 title+URL TU)和多种适配方法(Full FT、LoRA),首次系统性量化了 GenIR 在持续学习下的 stability-plasticity trade-off; 2. 提出 PAMT 框架——"先适配主干,再用一个 memory-only 的稳定阶段做后置校准",避免在 stabilization 阶段重放遗失的相关性监督; 3. 设计 PMH(基于 product-key memory,PKM),让 stabilization 阶段只更新经过 AF×IHF 排序后选中的稀疏 value 行,限制跨 slice 干扰。
前置定义与问题形式化¶
GenIR 基本设定¶
设文档集 $\mathcal{D}=\{d_1,\ldots,d_{|\mathcal{D}|}\}$,查询集 $\mathcal{Q}=\{q_1,\ldots,q_{|\mathcal{Q}|}\}$。每篇文档 $d$ 拥有 docid 序列 $I_d=(t_1,\ldots,t_{|I_d|})$,token 取自词表 $\mathcal{V}$。GenIR 用 encoder-decoder Transformer 建模条件分布:
$$ P(I\mid q;\theta)=\prod_{k=1}^{|I|}P(t_k\mid t_{<k},q;\theta)\tag{1} $$
训练目标是 cross-entropy 监督对 $\mathcal{S}$:
$$ \mathcal{L}(\theta)=-\sum_{(q,d)\in\mathcal{S}}\log P(I_d\mid q;\theta)\tag{2} $$
推理时构造 prefix trie $\mathcal{T}(\mathcal{D})$,在 beam search 每一步限制候选 token 到 trie-valid 集合 $A_k(\pi)\subseteq\mathcal{V}$,保证输出 docid 一定来自 $\mathcal{I}(\mathcal{D})$。
持续适配任务¶
整个语料按时间被切成互不相交的会话切片 $\mathcal{D}_i\cap\mathcal{D}_j=\emptyset$($i\neq j$):
- Session 0 ($t=0$):基础模型 $\theta_0$ 在初始语料 $\mathcal{D}_0$ 与查询 $\mathcal{Q}_0$ 上训练;
- Subsequent sessions ($t\geq 1$):新增 $\mathcal{D}_t$ 与对应查询 $\mathcal{Q}_t$,累计语料 $\mathcal{D}_{0:t}=\bigcup_{i=0}^t\mathcal{D}_i$,trie 也扩展为 $\mathcal{T}_{0:t}$。
stability:模型在历史切片 $\mathcal{D}_{0:t-1}$ 上的检索质量;plasticity:模型在新切片 $\mathcal{D}_t$ 上的能力。两者天然冲突。
Docid 方案¶
- Semantic Product-Quantized (SPQ) docids:用 SentenceTransformer E5-Mistral-7B-Instruct 把 "title + 前 50 句"嵌入,做 $\ell_2$ 归一化后用 PQ 量化($M=32$ 子段、每段 $K=256$ 中心点),得到长度 32 的 docid。词表扩展 $32\times 256=8192$ 个专用 token。新 slice 文档继续用 $\mathcal{D}_0$ 学到的码本做量化,因此各切片共享同一组语义 token,但容易出现编码碰撞。
- Title+URL (TU) docids:拼接最多 20 个 title token + 反序的 URL 路径段 + 二级域名,用 T5 tokenizer 切分后截到 100 子词。完全复用预训练词表,无需新加 token。
方法:Post-Adaptation Memory Tuning (PAMT)¶
PAMT 把适配过程分为两步:Stage 1 让主干自由学习当前 slice,获得 plasticity;Stage 2 冻结主干,仅在一个 modular 的 memory head 上做 value-only、sparse 的后置校准,恢复 stability。整个流程如 Figure 1 所示。
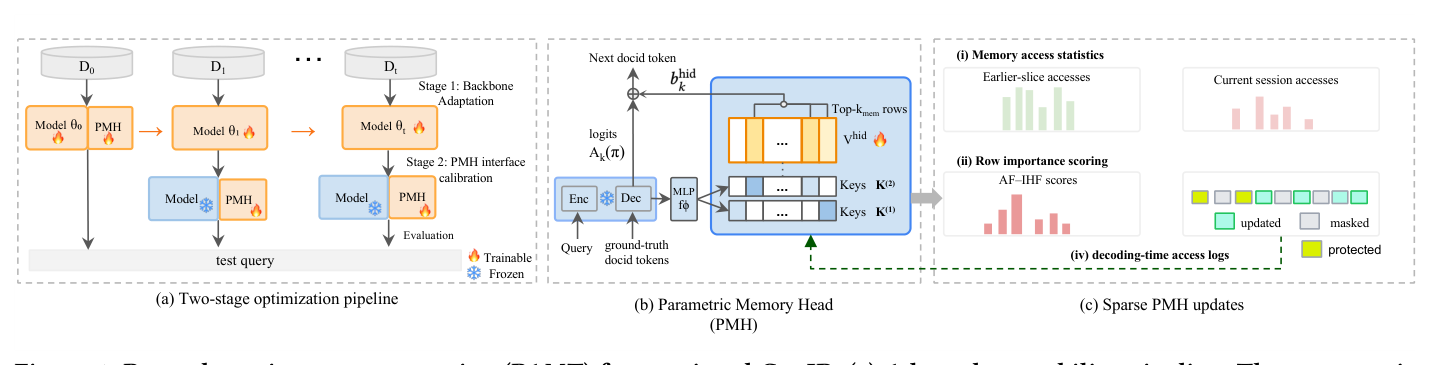
Stage 1:主干自适应¶
对每个会话 $t\geq 1$,在新切片 $\mathcal{D}_t$ 上对 GenIR 主干做标准微调,得到 $\theta_t$。这一步可以选 Full Fine-Tuning(更新全部主干参数 260M / 248M for SPQ / TU)或 LoRA(只更新 25.95M adapter 参数)。Stage 1 的目标只追求 plasticity:让模型在 $\mathcal{D}_t$ 上"会"检索新文档。
Stage 2:基于 PMH 的 memory-only 校准¶
4.1 Parametric Memory Head 的架构¶
PMH 是一个外挂在解码器旁边、与主干一起预训练(在 $\mathcal{D}_0$ 上)的 product-key memory 模块(PKM, Lample et al. 2019):
- 共享子键表 (Dual sub-key tables):两组 key 矩阵 $K^{(1)}=\{k^{(1)}_i\}_{i=1}^S$、$K^{(2)}=\{k^{(2)}_j\}_{j=1}^S$,$k^{(1)}_i,k^{(2)}_j\in\mathbb{R}^{d_\text{key}/2}$。每个 query 被劈成两半,分别与两组子键做点积,再组合形成 $(i,j)$ pair 的整体得分;这样只用 $2S$ 个子键就能寻址 $S^2$ 个 memory 行,存储/计算复杂度从 $O(S^2)$ 降到 $O(S)$。
- 隐空间 value 表:可学习矩阵 $V^\text{hid}\in\mathbb{R}^{S^2\times d}$,每行是一个 latent correction vector,存储 docid 解码时要施加的 hidden-space 修正。$V^\text{hid}$ 在 $\mathcal{D}_0$ 训练完后初始化,后续 Stage 2 的更新只动它的一小部分行。
- 共有 $H$ 个 query head,每 head 独立做产品键检索并取 top-$K_\text{mem}$。
4.2 解码时的三步流程¶
设解码到第 $k$ 步,主干(Stage 2 已冻结)输出隐藏状态 $h_k\in\mathbb{R}^d$,$E\in\mathbb{R}^{|\mathcal{V}|\times d}$ 为冻结的 output embedding 矩阵。
Step 1:Product-key 寻址。query 模块 $f_\phi$ 把 $h_k$ 投影到 $H$ 个 query 向量 $\{z_{k,h}\}_{h=1}^H$,$z_{k,h}\in\mathbb{R}^{d_\text{key}}$。每个 head 把 query 劈成 $z^{(1)}_{k,h},z^{(2)}_{k,h}\in\mathbb{R}^{d_\text{key}/2}$,对每个 key pair $(i,j)$ 算分:
$$ u_{k,h,i,j}=\langle z^{(1)}_{k,h},k^{(1)}_i\rangle+\langle z^{(2)}_{k,h},k^{(2)}_j\rangle\tag{3} $$
每个 head 取 top-$K_\text{mem}$ value 行 $\mathcal{S}_{k,h}=\text{TopK}(\{u_{k,h,i,j}\}_{i,j},K_\text{mem})$,并合并成 $\mathcal{S}_k=\bigcup_h\mathcal{S}_{k,h}$。注意 $(i,j)$ 会被展平成线性下标 $n=(i-1)\cdot S+j$。
Step 2:构建 latent correction。对每行 $\ell\in\mathcal{S}_{k,h}$ 取 $V^\text{hid}[\ell]\in\mathbb{R}^d$,按 head 内 softmax 归一化:
$$ \alpha_{k,h,\ell}=\frac{\exp(u_{k,h,\ell})}{\sum_{\ell'\in\mathcal{S}_{k,h}}\exp(u_{k,h,\ell'})}\tag{4} $$
加权求和 + 跨 head 求和得到隐空间修正向量:
$$ b_k^\text{hid}=\sum_{h=1}^H\sum_{\ell\in\mathcal{S}_{k,h}}\alpha_{k,h,\ell}V^\text{hid}[\ell],\quad b_k^\text{hid}\in\mathbb{R}^d\tag{5} $$
直观上 $b_k^\text{hid}$ 是一个轻量的 hidden-space 修正,用来 re-calibrate trie-constrained 解码下的 next-token 得分。
Step 3:Bias-guided constrained decoding。设 $\ell_k[\tau]$ 为主干给 token $\tau$ 的 logit、$A_k(\pi)\subseteq\mathcal{V}$ 为当前前缀允许的 trie-valid 续 token 集合。PMH 仅修改 $A_k(\pi)$ 内的 logit:
$$ \ell'_k[\tau]=\ell_k[\tau]+\langle b_k^\text{hid},E[\tau]\rangle,\quad\forall\tau\in A_k(\pi)\tag{6} $$
trie 之外的 token 仍由 trie mask 屏蔽。关键点:$E$ 在 Stage 2 全程冻结,所以 PMH 不可能"凭空创造"非法 token;其作用只是把 $A_k(\pi)$ 内合法候选的相对排序给重排一下。把投影限制在 $A_k(\pi)$ 上,额外计算量只随 trie 分支度而非整词表线性增长。
4.3 Post-adaptation memory tuning(Stage 2 的训练流程)¶
Stage 2 冻结主干 $\theta_t$、query 模块 $f_\phi$、product-key 表 $K^{(1)},K^{(2)}$ 与 output embedding $E$,唯一可训参数是 $V^\text{hid}$,而且只允许更新其中固定数量 $m$ 行。这样既不会动 Stage 1 已建立的 routing pattern,也不会重放历史相关性监督。
行选择:稀疏更新集 $\Omega_t$¶
PAMT 用 access-frequency × inverse historical frequency (AF×IHF) 给每行打分。
历史访问计数器 $\text{AF}_t^\text{hist}(n)$($n\in\{1,\ldots,S^2\}$)记录每行在历史会话中被检索过的次数:
$$ \text{AF}_t^\text{hist}(n)\leftarrow \text{AF}_{t-1}^\text{hist}(n)+\sum_{x\in\mathcal{X}_t}\mathbf{1}[\exists k:n\in\mathcal{S}_k(x)]\tag{7} $$
这里用"每条 query 至少出现一次"而不是"每个 token 步出现的次数",避免单条样本里反复命中的行被过度加权。
当前会话访问计数 $\text{AF}_t(n)$(基于 Stage 1 后的路由模式):
$$ \text{AF}_t(n)=\sum_{x\in\mathcal{X}_t}\mathbf{1}[\exists k:n\in\mathcal{S}_k(x)]\tag{8} $$
并按当前会话内总和归一化:
$$ \widehat{\text{AF}}_t(n)=\frac{\text{AF}_t(n)}{\sum_{n'=1}^{S^2}\text{AF}_t(n')}\tag{9} $$
历史计数则不归一化——其唯一作用是惩罚长期被频繁使用的行,降低它们再次被改写的概率。
保护集 $\mathcal{P}_t$ (do-not-change legacy rows):选历史使用率 top-$p$ 比例的行:
$$ \mathcal{P}_t=\text{TopP}\big(\{\text{AF}_t^\text{hist}(n)\}_{n=1}^{S^2},p\big)\tag{10} $$
它们在 Stage 2 中梯度被强制置零。剩余候选 $\mathcal{C}_t=\{1,\ldots,S^2\}\setminus\mathcal{P}_t$。
预算更新集 $\Omega_t$ (update only $m$ rows):从候选里取 AF×IHF 得分最高的 $m$ 行:
$$ w_t(n)=\widehat{\text{AF}}_t(n)\cdot\log\frac{Z+1}{\text{AF}_t^\text{hist}(n)+1},\quad n\in\mathcal{C}_t\tag{11} $$
其中 $Z=|\mathcal{X}_{<t}|$ 为历史 query 总数(IHF 项 $\log\frac{Z+1}{\text{AF}_t^\text{hist}(n)+1}$ 像 IDF 一样下调那些"老朋友" 行)。
$$ \Omega_t=\text{TopK}\big(\{w_t(n)\}_{n\in\mathcal{C}_t},m\big)\tag{12} $$
训练目标¶
仅用 $\mathcal{D}_t$ 的 query 监督,不重放历史。teacher-forced 解码下每步 logit 由公式 (6) 计算,对每个 trie-valid 正例 $y_k$,从同 trie 集合里随机抽 $\mathcal{N}_k$ 个负例,优化 hinge ranking loss:
$$ \mathcal{L}_\text{rank}=\sum_k\sum_{\tau^-\in\mathcal{N}_k}\max\big(0,\;\gamma-\ell'_k[y_k]+\ell'_k[\tau^-]\big)\tag{13} $$
其中 $\gamma>0$ 为 margin。梯度掩码保证只有 $\Omega_t$ 内的行更新:
$$ \nabla V^\text{hid}[n]\leftarrow\mathbf{1}[n\in\Omega_t]\cdot\nabla V^\text{hid}[n],\quad\forall n\in\{1,\ldots,S^2\}\tag{14} $$
三个机制保证不破坏旧切片¶
- Backbone & routing 冻结:Stage 2 不会引入额外 routing drift,所有改动仅是 trie-valid token 的 value 重排;
- 保护集 $\mathcal{P}_t$:长期被复用的"legacy 行"完全免疫梯度;
- 预算 $m$:限定每次更新只触动一小撮行,把跨 slice 干扰压到最低。
实验设置¶
数据集与持续切片¶
- 选用 MS MARCO Document Ranking(320K 子集,Wang et al. 预处理)和 Natural Questions (NQ320K)。
- 对每个语料切成 6 个互不相交的 slice:$\mathcal{D}_0$ 占 50%,$\mathcal{D}_1$–$\mathcal{D}_5$ 各占 10%。每个会话只用对应切片到达的 query 作训练监督,相关跨切片文档的 query 被丢弃,保证测试集 $\mathcal{Q}_{\text{test},t}$ 只包含相关文档落在 $\mathcal{D}_t$ 内的 query。
模型与 docid¶
- GenIR 主干:T5-base。SPQ docids 把 vocab 从 32128 扩到 40320(+8192 docid token)。TU docids 直接用 T5 tokenizer。
- Initial training:用 doc2query-T5-base-msmarco 给每个文档生成 10 个伪 query,与真实 query 一并构造 $(q,d)$ 对,AdamW (lr 1e-3) 训练 40 epoch。
- Constrained decoding:beam size 10。Expanded 协议每次只在 $\mathcal{T}(\mathcal{D}_{0:t-1})$ 中插入 $\mathcal{I}(\mathcal{D}_t)$;Fixed 协议直接用 $\mathcal{T}(\mathcal{D}_{0,n})$。SPQ 解码 cap 32 token,TU cap 100 token。
评估协议¶
下三角评估 (Lower-triangular):每个会话结束后在所有 $s\le t$ 的测试集 $\mathcal{Q}_{\text{test},s}$ 上计算 MRR@10,得到矩阵 $R^\text{MRR}_{t,s}$。同时报 Hit@10。三类聚合指标:
- Average Performance:$\text{AP}_n=\frac{1}{n+1}\sum_{s=0}^n R_{n,s}$
- Signed Backward Transfer:$\text{BWT}_n^\pm=\frac{1}{n}\sum_{s=0}^{n-1}(R_{n,s}-R_{s,s})$(理想为 0,负值代表遗忘)
- Diagonal Forward Performance:$\text{FWT}_{\text{diag},n}=\frac{1}{n}\sum_{s=1}^n R_{s,s}$(衡量新 slice 即时性能)
Stage 1 / Stage 2 / Baseline 配置¶
- Stage 1 (Full FT):AdamW,lr 5e-4,3 epoch,batch 64。
- Stage 1 (LoRA):rank 64,$\alpha=128$,dropout 0.05,lr 1e-3,10% warmup,3 epoch。LoRA 适配只在 $\psi_t$ 上展开,不与主干合并。
- Stage 2 (PAMT):每 head 取 $K_\text{mem}=32$ 个 value 行;$N_\text{mem}=S^2$ 行(PMH 总容量),保护比例 $p=10\%$,预算 $m=10{,}000$;hinge margin $\gamma=0.01$,$k_\text{neg}=4$;SGD lr 1e-3,2 epoch、10% 线性 warmup+衰减。Stage 2 在 MS MARCO / NQ 上分别只改写 6.25% / 17.95% 的 value 行。
- Baseline:(i) 索引型 BM25、DPR、DPR-HN(query encoder 每会话更新但文档 encoder 冻结);(ii) 非 PEFT continual GenIR:DSI++、CLEVER;(iii) PEFT continual GenIR:CorpusBrain++、PromptDSI、MixLoRA-DSI。
主要实验结果¶
RQ1:持续 GenIR 的 stability-plasticity trade-off¶
Figure 2 / Figure 3 综合展示了在 NQ / MS MARCO、Expanded / Fixed 两种协议、Full FT / LoRA × SPQ / TU 四种组合下,每会话每 slice 的 Hit@10。结论:
- 顺序 Stage 1 适配不可避免地放大遗忘:Full FT-SPQ 在 MS MARCO 上 BWT± = $-55.72$,NQ 上 $-35.95$,意味着早期 slice 性能塌方式下降。
- TU 比 SPQ 更稳定:在 MS MARCO 上 Full FT 把 BWT± 从 $-55.72$(SPQ)降到 $-38.43$(TU),NQ 上 $-35.95\to-25.93$。NQ 上 TU 还显著拉高 AP(15.38→31.59)。
- LoRA 通常比 Full FT 损失更小:MS MARCO 上 LoRA-SPQ BWT± = $-48.70$ vs Full FT-SPQ $-55.72$,但 NQ-TU 反例($-25.93$ vs $-32.90$)说明 docid 类型才是主导因素。
- Expanded vs Fixed 几乎相同:MS MARCO Full FT-SPQ BWT± Expanded $-55.72$ vs Fixed $-55.40$。说明只是 candidate set 增长无法解释退化。
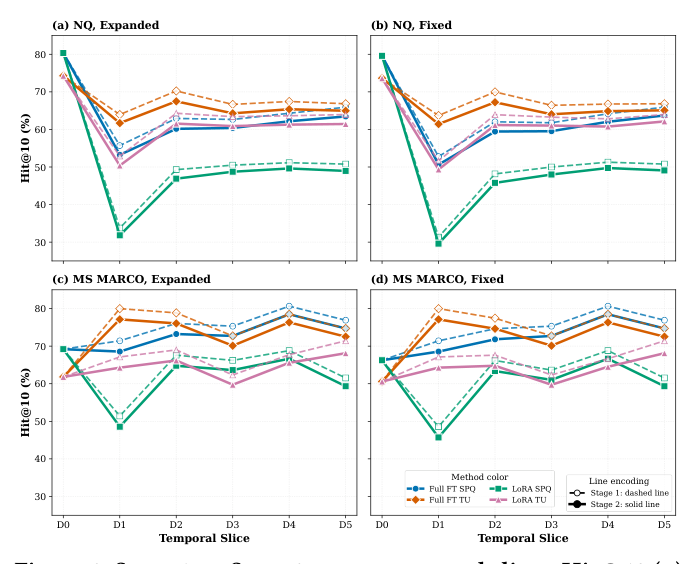
RQ2:PAMT 的稳定化效果¶
Figure 3 给出了汇总指标:
- Full FT-SPQ:MS MARCO BWT± 由 $-55.72$ 提升到 $-22.64$,NQ 由 $-35.95$ 提升到 $-14.21$。
- Full FT-TU:MS MARCO 由 $-38.43$ 升到 $-15.37$,NQ 由 $-25.93$ 升到 $-9.16$。
- LoRA 同样观察到对称的提升幅度。
- 与此同时,PAMT 对 diagonal 新 slice 性能影响有限:Expanded-MS MARCO Full FT-SPQ 的 AP 从 15.23 升到 31.45,Full FT-TU 由 31.59 升到 42.31,仅在 NQ 上有轻微 diagonal 牺牲。
解读:PAMT 的设计意图就是"不再学新 slice,而是把 Stage 1 已经掌握的能力保护住",因此 stability gain 几乎是无成本的。
RQ3:把退化拆成"搜索空间膨胀 / 标识符可迁移性 / 参数更新干扰"¶
作者用同一个 frozen $\theta_0$ checkpoint 跑两个无参数对照(结果见 Table 1):
| Dataset | docid | $\mathcal{D}_0$ Hit@10 | Frozen drop | Candidates | ZS Avg | Coll. rate |
|---|---|---|---|---|---|---|
| MS MARCO | SPQ | 69.21 | 2.95 | 152K → 301K | 5.64 | 7.45% |
| MS MARCO | TU | 61.82 | 1.23 | 158K → 315K | 14.46 | 2.37% |
| NQ | SPQ | 80.34 | 0.76 | 54K → 108K | 8.97 | 3.65% |
| NQ | TU | 74.28 | 0.66 | 55K → 110K | 20.25 | 1.84% |
- 搜索空间膨胀 (Frozen drop):candidate set 翻倍后 $\mathcal{D}_0$ Hit@10 仅下降 0.66–2.95 pp,远小于 BWT±(动辄 20+ pp 的损失)。
- 标识符 zero-shot 可迁移性:用 $\theta_0$ 直接对 future slice 用 slice-only trie 做解码,平均 Hit@10 仅 5.64–20.25,明显低于 $\mathcal{D}_0$ Hit@10。说明仅靠 $\theta_0$ 无法解码未来 slice 的 docid,要 plasticity 还得更新参数。
- 更新引发的干扰才是真正主因:上面两条加起来,最多解释几个 pp 的退化,剩余 $-30$ 至 $-50$ pp 都来自 query-docid 映射在 sequential update 中被覆盖。
值得注意的是 docid 设计同样影响 collision rate:SPQ 的 docs-affected collision 比 TU 高 ≈3×(MS MARCO 7.45% vs 2.37%),这部分解释为何 TU 在 later slice 上更稳定——因为 collision 越严重的 token 越容易被 update step 重新分配。
RQ4:与既有 baseline 的横向对比¶
Table 2(Expanded 协议)给出了 BM25 / DPR / DPR-HN / DSI++ / CLEVER / CorpusBrain++ / PromptDSI / MixLoRA-DSI 与 PAMT 的并排数据,分别报 D0–D5 的对角 Hit@10 与 AP / FWT_diag / BWT±。关键 takeaways:
- 索引型 baseline 因仍维护显式索引,最稳定:DPR-HN BWT± 仅 $-4.60$(MS MARCO)/ $-4.00$(NQ);
- 既有 continual GenIR baseline 全部明显遗忘:DSI++ MS BWT± $-32.45$、NQ $-28.74$;CLEVER $-26.38$/$-24.16$;MixLoRA-DSI $-22.94$/$-18.43$(已是 PEFT 中较稳的);
- PAMT 系列全面优于既有 continual GenIR baseline:PAMT-LoRA-TU 把 BWT± 拉到 $-11.23$(MS MARCO)/ $-10.84$(NQ),首次把 GenIR-style 检索器在 stability 上拉到与索引型 retriever 同一量级;
- PAMT-Full FT-TU 取得最高 AP(MS MARCO 37.26 / NQ 42.31)以及在 NQ 上几乎最佳的 BWT±($-9.16$),同时 FWT_diag 保持有竞争力的 49.62 / 65.38。
具体数据(节选 PAMT 行):
| Dataset | Method | D0 | D1 | D2 | D3 | D4 | D5 | AP | FWT | BWT± |
|---|---|---|---|---|---|---|---|---|---|---|
| MS MARCO | PAMT-LoRA-SPQ | 69.21 | 48.57 | 64.79 | 63.64 | 66.67 | 59.34 | 25.18 | 50.43 | -19.82 |
| MS MARCO | PAMT-LoRA-TU | 61.82 | 64.29 | 66.20 | 59.74 | 65.59 | 68.13 | 32.94 | 52.76 | -11.23 |
| MS MARCO | PAMT-Full FT-SPQ | 69.21 | 68.57 | 73.24 | 72.73 | 78.49 | 74.73 | 31.45 | 61.87 | -22.64 |
| MS MARCO | PAMT-Full FT-TU | 61.82 | 67.14 | 76.06 | 70.13 | 76.34 | 72.53 | 37.26 | 61.58 | -15.37 |
| NQ | PAMT-LoRA-SPQ | 80.34 | 31.82 | 46.90 | 48.75 | 49.62 | 48.96 | 19.47 | 31.24 | -13.56 |
| NQ | PAMT-LoRA-TU | 74.28 | 50.39 | 61.55 | 60.90 | 61.28 | 61.45 | 31.28 | 47.62 | -10.84 |
| NQ | PAMT-Full FT-SPQ | 80.34 | 53.25 | 60.17 | 60.40 | 62.18 | 63.46 | 27.83 | 39.15 | -14.21 |
| NQ | PAMT-Full FT-TU | 74.28 | 61.69 | 67.48 | 64.29 | 65.38 | 64.97 | 42.31 | 52.87 | -9.16 |
6.5 灵敏度分析:保护比例 $p$ 与更新预算 $m$¶
Table 3(MS MARCO + SPQ + Expanded):
| $p$ | $m$ | AP | FWT_diag | BWT± |
|---|---|---|---|---|
| 0% | 2,000 | 27.80 | 59.92 | -29.84 |
| 0% | 10,000 | 29.76 | 62.44 | -26.31 |
| 0% | 50,000 | 29.98 | 62.73 | -25.88 |
| 10% | 2,000 | 29.34 | 59.46 | -25.71 |
| 10% | 10,000 | 31.45 | 61.87 | -22.64 |
| 10% | 50,000 | 31.66 | 62.02 | -22.31 |
| 30% | 2,000 | 29.08 | 56.91 | -23.96 |
| 30% | 10,000 | 30.84 | 59.28 | -20.87 |
| 30% | 50,000 | 31.02 | 59.41 | -20.51 |
| 50% | 2,000 | 26.92 | 52.43 | -24.68 |
| 50% | 10,000 | 28.47 | 54.96 | -21.93 |
| 50% | 50,000 | 28.59 | 55.11 | -21.61 |
要点:
- $p=0\%$(不保护)BWT± 总是更差,证实保护"老朋友" 行能换来稳定性;
- $p=30\%$ 时 BWT± 最优($-20.51$ at $m=50\text{K}$),但 AP 与 FWT_diag 略落后于 $p=10\%$;
- $p=50\%$ 过度保护导致剩余可调容量不足,所有指标都下降;
- 沿 $m$ 轴:$m=10\text{K}$ 已经吃到大部分收益,从 $m=10\text{K}$ 增到 $m=50\text{K}$ 仅多换 0.21 AP / 0.33 BWT±;
- 默认设定 $p=10\%$、$m=10\text{K}$ 是 AP 接近最优、保持稀疏的一个平衡点。
讨论与局限性¶
核心贡献的解读¶
PAMT 提供了 GenIR 持续学习的一个新视角:stability 不必通过 rehearsal 或额外 backbone 训练实现。Stage 2 的所有约束(trie 限制、output embedding 冻结、product-key 路由冻结)合起来意味着"PMH 只能 re-rank trie-valid 的合法 token",所以它不会引入新的语义漂移。AF×IHF 的稀疏选行类似一个轻量级"重放"——历史使用模式直接通过访问统计沉淀进 $\text{AF}_t^\text{hist}$,不需要保存原始 query 或 docid。这种"统计 rehearsal"既绕开了用户隐私问题(Kissner & Stone 2025),又避免了 storage cost 随 slice 数量线性增长。
设计哲学:为什么 Stage 2 不再继续 backbone 优化?¶
一旦 Stage 1 改完了主干,PMH 的路由(query module + product keys)也跟着 Stage 1 训练阶段的 routing 模式。Stage 2 把所有 routing 都冻住,只让 value 行变化,等于"路由结构沿 Stage 1 的最新结果走,logit 修正沿当前 slice 的需求微调"。这种解耦是 PAMT 与 DSI++/CorpusBrain++ 等"在主干内塞 adapter"路线的核心区别:后者一旦更新,仍会改动 routing;PAMT 的 PMH 完全不影响主干 routing,于是 stability 的边界条件被卡得更死。
局限与未来方向¶
作者列出了五个公开方向:
- 超参选择:$p$、$m$ 目前仍是固定值,未来可考虑按 slice novelty / PMH access divergence 自适应;
- 更细粒度的诊断:Stage 1 引发的 routing drift 仅通过 BWT± 间接观察,缺少对 PMH 路由变化、anchor-based routing 或 access regularization 的显式量化;
- 系统 cost:论文没报 wall-clock cost / 推理延迟。PMH 的投影只在 trie-valid token 上做,因此理论开销有限,但需要工程验证;
- 保护策略:硬保护 top-$p$ 行可以换成"基于历史重要度的 soft scaling",更好兼顾陈旧映射与有意遗忘;
- 横向扩展:实验只覆盖 320K 量级语料、5 个 session、两种 docid,更长 horizon、更大语料、joint-retraining upper bound 仍是 open problem。
与 DACT 等 continual generative 系统的关系¶
详见后文与已归档相关工作的对比章节。两者都属于"freeze + selectively-update"派系,但作用域完全互补——DACT 维护 标识符 的稳定性,PAMT 维护 backbone 解码 的稳定性,理论上可以叠加。
与已归档相关工作的对比¶
DACT DACT (Fudan University, 2026-03-31)¶
关系:独立并发(本文未引用 DACT,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都直面"持续学习场景下,生成式检索/推荐如何在引入新文档/新物品的同时保留历史 query/user 表示"——亦即 plasticity-stability trade-off 的根因都是"GenIR/GR 把所有映射隐式编码到神经网络参数里",导致简单的顺序微调会被新数据覆盖。两者也都坚持"避免 rehearsal、避免完整重训"作为约束条件。
- 相近的技术骨架:两者都采用"识别一小撮真正需要变的单元 + 强制其余不变"的 sparse selective update 模式:DACT 用 CDIM 选漂移物品的 token、PAMT 用 AF×IHF 选 PMH 中的 value 行。两者都引入了"保护层"概念(DACT 在 anchor loss 中保护 stable items 的 latent representation;PAMT 用 $\mathcal{P}_t$ 保护 top-$p$ 历史高频 row)。两者都在保留主体网络(DACT 保留 GRM、PAMT 保留 backbone)的前提下改动一个轻量结构(DACT 改 tokenizer code、PAMT 改 PMH value)。
- 本文的差异与推进:DACT 的可调对象是 标识符 本身——它通过 Stage 2 重分配 RQ-VAE code 来反映新协同信号;PAMT 完全不动标识符(trie 由 docid scheme 固定),改动的是 decoder 输出端的隐空间 bias。这导致两个 trade-off 不一样:DACT 必须容忍部分 GRM 重训(因为新 token 序列要让 GRM 学会读),而 PAMT 完全跳过 backbone 重训,stability 损失更小但 plasticity gain 较受限(必须靠 Stage 1 拿到)。从适配粒度看,DACT 是"per-item 决策(更新 / 保留 token)",PAMT 是"per-row 决策(更新 / 冻结 latent correction)",两者粒度互补。
- 可比的方法 / 实验差异:DACT 在 Amazon Beauty/Tools/Toys 用 Hit@k / NDCG@k 评估,PAMT 在 MS MARCO / NQ 用 MRR / Hit@10 + AP / BWT± / FWT。DACT 验证了 selective update 在 tokenizer adaptation 阶段奏效;PAMT 验证了同样的范式在 post-adaptation memory tuning 阶段同样奏效。两者并不互相替代——DACT 解决的是"新物品涌入时 token 一致性"问题,PAMT 解决的是"任意持续学习场景下 GenIR 主干干扰"问题。一个工业系统理论上可以同时使用 DACT 维护 SID 稳定,再用 PAMT 维护检索行为稳定。