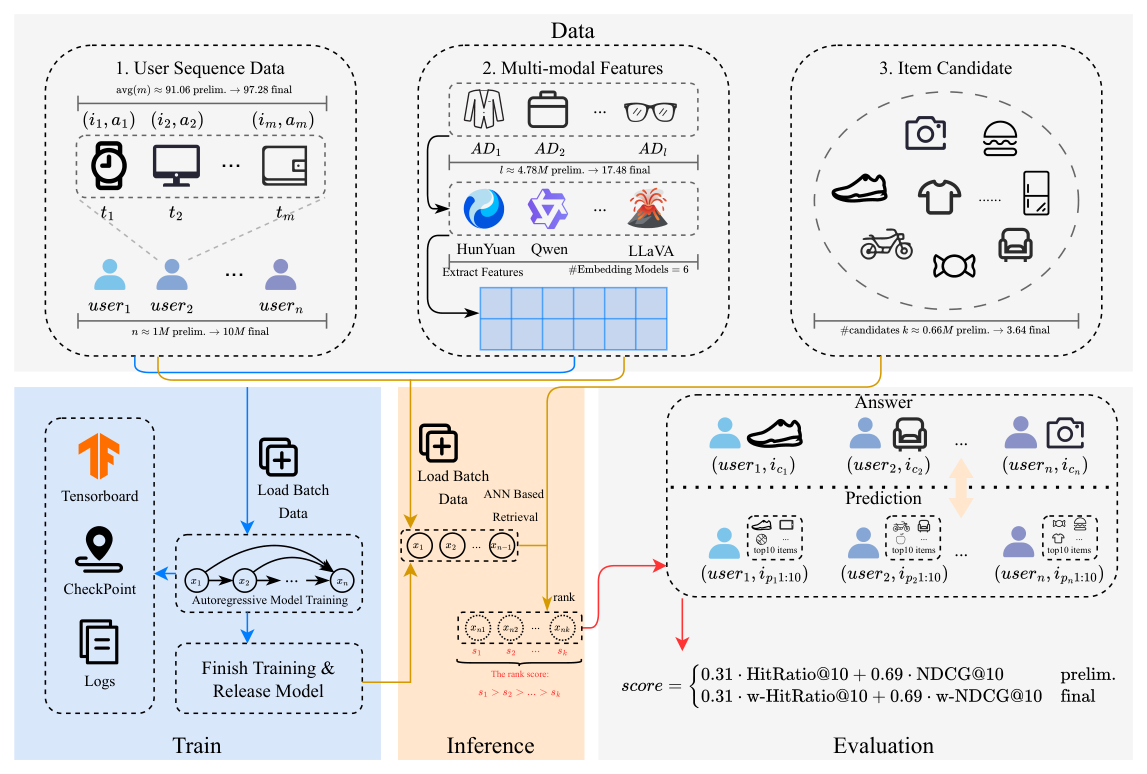
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation¶
一、背景与动机¶
判别式推荐模型(discriminative recommender)长期主导工业推荐系统,主要演进方向是更具表达力的特征交互建模(DCN、DLRM、DeepFM、Wukong 等)和基于序列的用户兴趣建模(DIN、DIEN、SIM 等)。近两年生成式推荐(Generative Recommendation,GR)则提出一种新范式:将候选重排序或召回问题转为一次基于物品 ID 或语义 code 的序列生成,按自回归解码方式吐出用户下一个行为物品。典型代表包括:
- 语义 ID 方法:TIGER、LETTER、DAS、MMQ、OneRec 等;
- 并行语义 ID:结合多模态信号与协同信号生成可用于检索排序的 token 序列。
作者指出,当前大量 GR 研究仍基于中小规模电商语料(Amazon Beauty/Toys/Sports、Yelp 等),物品表示通常只是"单模态 ID + 稀疏 metadata";大规模全模态数据集(如 MIND、KuaiRand、KuaiRec、Tenrec、WWW'25 short-video dataset)要么只有 CTR/序列任务,要么没有完整多模态 embedding,要么没有工业广告场景特有的转化(conversion)信号。因此,面向工业广告、包含全模态表征、同时建模点击与转化的大规模公开 GR benchmark 仍然缺失。
为此,腾讯组织了 Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation,并发布两个配套数据集:
- TencentGR-1M:初赛数据集,100 万用户序列,每条序列至多 100 个交互物品,标注
exposure与click。 - TencentGR-10M:决赛数据集,1 000 万用户序列,同时区分
click与conversion,把转化事件显式建模到序列与预测目标中。
两者均来自脱敏的腾讯广告真实日志,包含稀疏 ID、类别属性、以及用 SOTA embedding model 抽取的文本/图像多模态 embedding。数据集发布在 HuggingFace (TAAC2025/TencentGR-1M、TencentGR-10M),baseline 代码发布在 GitHub (TencentAdvertisingAlgorithmCompetition/baseline_2025),官方站点 https://algo.qq.com/2025。
二、比赛设定¶
2.1 问题定义¶
比赛的核心任务是多模态交互序列下的 next-item 推荐。对每个用户 $u$,观察到一条按时间排序的广告行为序列(impression、click、conversion):
$$S_u = \{x_u, x_{u,1}, x_{u,2}, \dots, x_{u,T_u}\} \tag{1}$$
其中 $x_u$ 是聚合静态画像特征的 user-profile token,$x_{u,t}$ 是时刻 $t$ 对应的 item token(本质对应一次 impression)。item-side 特征进一步拆为:
$$ \begin{aligned} x_u &= \bigl( f_{\text{pf}}^{(1)}, \dots, f_{\text{pf}}^{(K_{\text{pf}})} \bigr), \\ x_{u,t} &= \bigl( f_{\text{cate}}^{(1)}, \dots, f_{\text{cate}}^{(K_{\text{cate}})}, f_{\text{act}}, f_{\text{imm}}^{(1)}, \dots, f_{\text{imm}}^{(K_{\text{imm}})} \bigr), \end{aligned} \tag{2} $$
其中 $f_{\text{pf}}$ 是用户画像特征(年龄、性别等),$f_{\text{cate}}$ 是类别属性(ID、广告主、产品类目等),$f_{\text{act}}$ 是行为/反馈信号(exposure、click、conversion),$f_{\text{imm}}$ 是预计算的文本/图像多模态 embedding。记 $K_{\text{pf}}, K_{\text{cate}}, K_{\text{imm}}$ 为每条 token 对应的 profile、类别、多模态特征数。给定序列前缀 $S_u$,参赛系统要从大规模候选池预测 $x_{u,T_u+1}$,即用户下一个最可能点击(或转化)的物品。
2.2 比赛赛程¶
比赛组织为两轮在线评测 + 一次线下决赛:
- 初赛(Preliminary round):使用 TencentGR-1M,目标是预测下一次点击。参赛者在本地训练、在私有测试集上提交预测结果。官方 leaderboard 使用 HitRate@10 与 NDCG@10 的加权组合作为最终得分。Top 50 队伍可进入决赛,评估时不对行为加权。
- 决赛(Second round):使用 TencentGR-10M,任务升级为 next click-or-conversion prediction。由于 impression 中同时存在点击与转化,要求参赛者把转化视为更高价值的预测目标,评估协议用严格的黑盒测试集,使用的指标体系与初赛相似但引入 behavior-type 加权,以额外奖励正确预测转化的模型。官方后续对前 20 名队伍做代码 review 与复现性验证,通过者受邀线下答辩。
- 线下决赛:入围者向评审委员会展示方法和结果,最终排名为 75% 线上 leaderboard 分数 + 25% 技术创新/清晰度/潜在影响的委员会打分 的加权和。
2.3 奖项与人才项目¶
比赛奖金结构:
- 冠军 2 000 000 RMB,亚军、季军各 600 000 / 300 000 RMB;
- 第四至第十名每队 100 000 RMB;
- 另设 Technical Innovation Award 200 000 RMB,奖励在多模态生成式推荐方向上具备原创性、方法突破性的解决方案;
- 决赛所有成员获得腾讯 on-site interview 机会,Top 10 队伍可获正式全职 offer,进入决赛者可获实习 offer,对因毕业时间或学业冲突无法立即入职的选手,腾讯按 case-by-case 发放长期意向书。
2.4 参赛规则¶
比赛面向全球在读本硕博和合格博士后研究员,每人最多加入一支队伍,每队 1–6 人。比赛要求提交完整代码以保证复现性;明确禁止模型集成(model ensembling),强调"设计良好的单模型"而非刷分用的大 ensemble,避免工业实时推荐难以部署的套路。参赛者需使用生成式建模思路——自回归架构或生成式语义 ID 构造,而非纯判别模型。提交训练/推理代码会在进入决赛前被人工审阅。
三、数据集构造¶
3.1 初赛 TencentGR-1M¶
序列与目标构造。从腾讯广告日志中采样 1 001 845 位在 answer time window 内至少有一次点击的用户。对每位用户,定位其第一次点击所在的 impression 为预测目标;用户对应的历史被定义为目标 impression 之前的所有行为(impression 与 click),按时间排序并截断到最多 100 个 item token,作为观测序列。
User / Ad 特征。user token 聚合用户人口属性与长期兴趣;item token 聚合稀疏协同 ID、产品 metadata 及多模态 embedding。下表(Table 2)给出特征 schema,其中 "S" 表示单值类别特征,"M" 表示多值类别特征。
Action type。TencentGR-1M 中 item token 的 action 标签 $r_{u,t} \in \{0,1\}$ 分别对应 exposure 与 click:点击占 9.81%,未点击 impression 占 90.19%。
候选集构造。评估时每个用户关联到一个全局去重、大小 660 k 的候选集。首先保证每个 ground-truth 目标物品在候选集中,之后从 ad 日志里继续抽非目标物品,使得大约 40% 的候选来自真实曝光、60% 为负样本,兼顾检索难度与多样性。
数据集基本统计(Table 1):
| 统计量 | TencentGR-1M | TencentGR-10M |
|---|---|---|
| # users | 1,001,845 | 10,139,575 |
| # ads | 4,783,154 | 17,487,676 |
| max sequence length | 100 | 100 |
| avg sequence length | 91.06 | 97.29 |
| # candidate ads | 660,000 | 3,637,720 |
| action type | exposure (90.19%), click (9.81%) | exposure (94.63%), click (2.85%), conversion (2.52%) |
结论:从规模上看,TencentGR-10M 在用户、广告、候选池三个维度均为初赛的 3×–10× 放大;更关键的是 10M 引入了 conversion 事件,但其样本占比仅 2.52%,显著低于 click 的 2.85%,说明高价值行为天然稀疏,直接按样本数训练会让模型偏向 impression。这正是决赛需要引入加权评估的动机。
3.2 决赛 TencentGR-10M¶
序列与目标构造。TencentGR-10M 的时间窗口和特征 schema 与 1M 版本一致,但用户规模放大 10 倍。对每个用户,重新选择 reference time $t_{\text{begin}}$ 并搜索该时间之后最早的合格目标事件:若存在转化事件,则把该转化关联回触发它的 impression,将整条 impression-click-conversion 链路视为"下一步行为";否则与初赛一致,按 click 定义目标。该归因策略与工业界惯用的转化归因一致。对 impression 做截断后,其对应的后续 conversion 或 click 作为预测目标。
值得注意的是:conversion 既出现在用户历史序列中,也作为预测目标类型之一存在。这正是 TencentGR-10M 区别于初赛、也区别于大多数公开 GR 数据集的关键点。
Action type。TencentGR-10M 中所有 item token 都带有 $r_{u,t} \in \{0,1,2\}$:exposure、click、conversion。统计上仅 2.52% 是 conversion,但评估将给其更高的权重(见 6.2)。
候选集构造。10M 的全局候选池达到 3 637 720 条去重广告。构造规则与 1M 一致:保证 ground-truth 在池内,其余来自整个 ad 日志抽样,复现真实检索场景的难度。
3.3 多模态特征¶
原始 ad creatives 包含文本(标题、描述)、图像,有时还有视频,出于广告主隐私和存储带宽考虑不会直接公开。官方用六个生产级 embedding model 对每条广告抽取表征,只发布 embedding 向量。六个模型见 Table 3:
| Emb. ID | Model | Modality | Params | Dim |
|---|---|---|---|---|
| 81 | Bert-finetune | T | 0.3 B | 32 |
| 82 | Conan-embedding-v1 | T | 0.3 B | 1 024 |
| 83 | gte-Qwen2-7B-instruct | T | 7 B | 3 584 |
| 84 | hunyuan_mm_7B_finetune | I | 7 B | 4 096 / 32 |
| 85 | QQMM-embed-v1 | I | 8 B | 3 584 |
| 86 | UniME-LLaVA-OneVision-7B | I | 8 B | 3 584 |
注意 84 号 hunyuan_mm 的 embedding 在 TencentGR-1M 上按 4 096 维发布,在 TencentGR-10M 上降为 32 维。每条广告最多会挂 6 个 embedding,但不同广告的 coverage 不同。
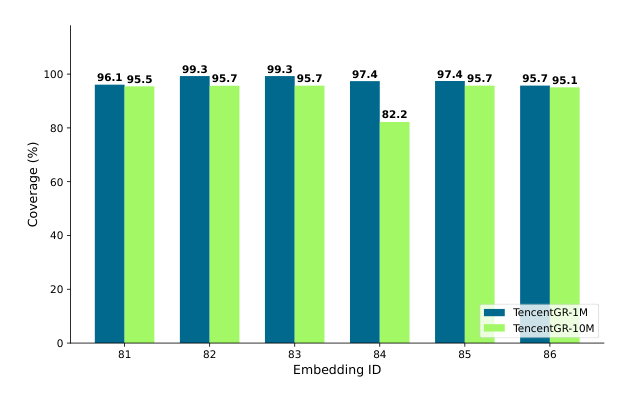
结论:82/83/85 号模型在两个数据集上都有 ~95% 的覆盖率,是较为可靠的核心特征;84、86 号覆盖率略低(~82%–90%),在模型侧需要做缺失 embedding 的容错。
其中 Bert 和 Hunyuan 两个模型是用腾讯自家基于整个广告协同信号微调的,迁移到广告点击/转化任务上的先验更强;其余四个模型是无监督或通用领域预训练的,未经过协同信号 finetune。
四、Baseline 模型¶
比赛同时放出了一个参考实现,降低参赛门槛。Baseline 按 next-token prediction 公式化,使用标准 Causal Transformer 作为骨干,结合 ANN 近邻检索 做 serving。
4.1 训练¶
序列构造。遵循 Equation (1),每个用户的输入是 user-profile token 加若干 item token,item token 包含共享 schema 定义的 sparse + multi-modal 特征。
Feature encoding。按 Equation (2) 对每个 token 做 multi-feature fusion。每个类别/ID feature field 都有独立的 embedding table,multi-modal embedding 则直接使用官方发布的连续向量。对 user-profile token $x_u^0$,将所有 profile 特征的 embedding 拼接后过一个小 MLP 投到统一的 token embedding 空间;对 item token $x_{u,t}^0$,同样把类别特征 embedding 与多模态 embedding 拼接后 MLP:
$$ \begin{aligned} \mathbf{e}_f &= \mathrm{Emb}(f), \quad \forall f \in \mathcal{F}, \\ x_u^0 &= \mathrm{MLP}\!\left( \operatorname{concat}\!\big( \{\mathbf{e}_f\}_{f \in \mathcal{F}_u} \big) \right), \\ x_{u,t}^0 &= \mathrm{MLP}\!\left( \operatorname{concat}\!\big( \{\mathbf{e}_f\}_{f \in \mathcal{F}_{u,t}}, \{f_{\text{imm}}^{(j)}\}_j \big) \right), \end{aligned} \tag{3} $$
其中 $\mathcal{F}_u$ 是 user profile 特征集合,$\mathcal{F}_{u,t}$ 是第 $t$ 步 item 的类别特征集合,$f_{\text{imm}}^{(j)}$ 是第 $j$ 个预计算多模态 embedding。最终 $x_u^0$ 与 $x_{u,t}^0$ 作为每个 token 的初始表示送入 Transformer 骨干。
Backbone 架构。Baseline 使用一个 causal Transformer。先把 user-profile token 与所有 item token 的初始表示加上位置编码 $\mathbf{p}_t$ 形成初始隐状态:
$$\mathbf{H}^0 = \big[ x_u^0 + \mathbf{p}_0, \ x_{u,1}^0 + \mathbf{p}_1, \ \dots, \ x_{u,T_u}^0 + \mathbf{p}_{T_u} \big], \tag{4}$$
然后叠加 $L$ 层带 causal mask 的 Transformer:
$$\mathbf{H}^l = \mathrm{TransformerLayer}^l(\mathbf{H}^{l-1}), \quad l = 1, \dots, L. \tag{5}$$
用户在第 $t$ 个位置的最终表示取自最后一层隐状态:
$$\mathbf{h}_{u,t} = \mathbf{H}^L[t], \tag{6}$$
作为预测第 $t+1$ 个物品的 user state。
训练目标。对每个训练 instance $(u,t)$,取处理完前 $t$ 步后所产生的用户表示,预测紧随其后的 impression 物品 $i^*$ 作为正样本。从全局物品池均匀采样 $N_{u,t}$ 个负样本,构造 InfoNCE 损失:
$$\mathcal{L} = - \sum_{(u,t)} \log \frac{\exp(s_{u,t,i^*})}{\exp(s_{u,t,i^*}) + \sum_{i^- \in N_{u,t}} \exp(s_{u,t,i^-})}. \tag{7}$$
该目标鼓励正样本相对随机负样本得分更高,与比赛采用的检索式评估指标天然对齐。
决赛版损失。在 TencentGR-10M 上,baseline 对不同 action type 引入权重 $w_a$,使 conversion 正例对 loss 的贡献更大:
$$\mathcal{L} = - \sum_{(u,t,a)} w_a \cdot \log \frac{\exp(s_{u,t,i^*})}{\exp(s_{u,t,i^*}) + \sum_{i^- \in N_{u,t}} \exp(s_{u,t,i^-})}, \tag{8}$$
其中 $w_a$ 为 action $a$ 的损失权重。
实现细节。baseline model 使用单层 Transformer($L=1$),隐维 $d=32$;attention heads 设为 1;dropout 0.2;历史序列截断或 pad 至固定长度 101;item embedding 与位置 embedding 均可学习;优化器 Adam,学习率 0.001;遵循标准序列推荐协议,每个正样本配 $N_{u,t}$ 个来自全词表均匀分布的负样本;使用 PyTorch 实现,单卡高端 GPU 训练;完整配置与超参数随 baseline 代码发布。
4.2 推理¶
推理阶段,用户表示学习和物品检索是解耦的:
- User embedding。把用户历史过 Transformer,取最后位置的最后一层 hidden state 作为当前 context 下的用户 embedding。
- Candidate item embedding。对候选集每个物品,复用训练中相同的特征编码器拿到物品 embedding,可离线预计算并缓存。
- Approximate nearest neighbor search。在所有物品 embedding 上建 ANN index,serving 时用 user embedding 作 query,用 Faiss 做 top-$K$ 检索。
五、竞赛平台¶
比赛的训练/评估全部跑在腾讯 Angel 分布式机器学习平台上。Angel 为比赛提供了三类能力:
- 参考实现:包括数据加载、baseline training、baseline evaluation 的脚本;
- 虚拟化 GPU 资源:通过 vGPU 机制按物理卡 0.2 为粒度提供资源,单队最多可同时使用 0.2 到 7 张高性能 GPU,赛期内做到细粒度共享;
- 高吞吐执行:赛期内 Angel 总共执行了数十万次训练/评估作业,维护稳定服务。
评估测试集对参赛选手严格沙盒隔离。参赛者提交的 inference container 从指定目录读入测试集,把预测写入预定义的 JSON 格式;container 无网络访问,也无法写到指定输出目录之外,从而防止泄漏或执行未授权程序。每支队伍每 24 小时最多提交 3 次;leaderboard 每天用前 24 小时内的最佳得分刷新。比赛规定禁止利用平台漏洞、非授权数据、或绕过提交次数限制的行为,违者分数作废乃至取消资格。
六、评估协议¶
6.1 初赛评估指标¶
初赛任务是 next-click prediction,所有 click 事件视为相关信号。采用标准序列推荐 benchmark 的 HitRate@K 与 NDCG@K,不做 behavior 加权。设 $G_u$ 为用户 $u$ 真实下一次点击的物品,$\hat{y}_{u,1}, \dots, \hat{y}_{u,K}$ 为模型对该用户从候选集 top-$K$ 的预测:
- HitRate@K:衡量正确物品是否出现在 top-$K$ 中:
$$\mathrm{HitRate@K}(u) = \mathbb{I}\{G_u \in \{\hat{y}_{u,1}, \dots, \hat{y}_{u,K}\}\}. \tag{9}$$
最终 HitRate 对所有用户取平均。
- NDCG@K:因为每个用户只有一个相关物品,NDCG@K 简化为:
$$\mathrm{NDCG@K}(u) = \sum_{k=1}^{K} \frac{\mathbb{I}\{\hat{y}_{u,k} = G_u\}}{\log_2(k+1)}. \tag{10}$$
同样对所有用户取平均。
初赛 leaderboard 组合分。官方 leaderboard 排名使用如下加权组合:
$$\mathrm{Score}_{\text{prelim}} = 0.31 \cdot \mathrm{HitRate@10} + 0.69 \cdot \mathrm{NDCG@10}. \tag{11}$$
系数是在内部 baseline 集合上标定的——使 HitRate@10 和 NDCG@10 两项对总分有近似等量贡献。作者先在多组训练/评估模型上分别算两个指标的平均值,再选取权重使乘以权重后的两项均值大致相等。作者还实证对比了 $K=100$,发现 $K=10$ 在各种模型之间有更大的变异系数(即 leaderboard 区分度更高),最终所有官方指标都以 $K=10$ 上报。
6.2 决赛评估指标¶
6.2.1 加权 HitRate 与 NDCG¶
决赛延伸相关性定义,把 click 与 conversion 都算作正样本,但赋予不同权重。设 $G_u$ 为用户 $u$ 所有 ground-truth target 物品集合(包括 click 与 conversion),$\hat{y}_{u,1}, \dots, \hat{y}_{u,K}$ 为模型预测的 top-$K$。定义权重函数 $w(i)$,根据 action type 给每个物品打权:
$$w(i) = \begin{cases} 0, & \text{如果 } i \text{ 只是 exposure,} \\ 1, & \text{如果 } i \text{ 是 click,} \\ \alpha, & \text{如果 } i \text{ 是 conversion,} \end{cases} \tag{12}$$
其中 $\alpha = 2.5$,用以反映转化行为的更高价值。加权 HitRate@K 对用户 $u$ 定义为:
$$\text{w-HitRate@K}(u) = \frac{\sum_{k=1}^{K} w(\hat{y}_{u,k}) \cdot \mathbb{I}\{\hat{y}_{u,k} \in G_u\}}{\sum_{i} w(i)}, \tag{13}$$
再对所有用户取平均。对 NDCG 同样加权:先算 w-DCG@K,然后 w-IDCG@K,最后取比值作为 w-NDCG@K:
$$\text{w-DCG@K}(u) = \sum_{k=1}^{K} \frac{w(\hat{y}_{u,k}) \cdot \mathbb{I}\{\hat{y}_{u,k} \in G_u\}}{\log_2(k+1)}, \tag{14}$$
$$\text{w-IDCG@K}(u) = \sum_{k=1}^{\min(K, |G_u|)} \frac{w(i^*_k)}{\log_2(k+1)}, \tag{15}$$
其中 $i_1^*, i_2^*, \dots$ 是把 $G_u$ 中物品按 $w(i)$ 降序排列得到的理想序列,
$$\text{w-NDCG@K}(u) = \frac{\text{w-DCG@K}(u)}{\text{w-IDCG@K}(u)}, \tag{16}$$
再对所有 $u$ 平均。
6.2.2 决赛 leaderboard 组合分¶
决赛沿用初赛的 31% / 69% 权重组合,但两个分量分别替换为 w-HitRate@10 与 w-NDCG@10。在决赛数据集上,两项指标同样是在内部 baseline 集合上重新标定过的,保证贡献近似均衡。
关键是:决赛中提交模型只能隐式感知 action type——官方不把训练样本里每条行为的权重直接暴露给参赛者,而是维护从用户 ID 到其 ground-truth 行为类型的映射,仅在评估 pipeline 中用来计算相关权重。这既强制参赛者通过模型学到 "哪些物品更可能成为 conversion",又避免了通过硬编码标签灌水的作弊路径。
七、比赛总结与 Top 方案¶
本届比赛吸引 8 440 注册参赛者,覆盖将近 30 个国家与地区,其中 140 所大学来自中国大陆(含港澳台),另有 340 所来自海外,总共 2 800 队伍中 4 600 支在比赛期间至少有一次有效提交。参赛者所在院校中,产出决赛队伍最多的五所为 USTC、清华、中科院大学、浙大、复旦。
下文按官方报告简要总结前三名和 Technical Innovation Award 获得者的核心建模思路。
7.1 第一名¶
冠军方案在 dense Transformer backbone 上做了一个全模态自回归 GR:
- 引入基于行为类型的条件建模机制:以 action 类型作为条件信号驱动 gated FiLM 层([1]),用于调制 item 表示;并对 attention 做 bias,使模型能解耦不同行为下的 item 语义;
- 设计了一种时间特征层级结构,捕捉时间戳各粒度的周期性——session、跨天访问 session 以及用小频率 Fourier feature 编码得到的周期性信号,以更好地区分 short-tail 长尾物品;
- RQ-k-Means:对多模态 embedding 做 residual quantized $k$-means([35]),生成 next-item 的语义 ID 供生成;
- 使用 hybrid Muon [24] + AdamW [34] 优化器,搭配 static-shape、GPU-friendly 对比 InfoNCE loss([40])和 large negative banks;推理阶段进行端到端的用户向量生成,后接 ANN 检索,在性能与资源使用间取得良好折衷。
7.2 第二名¶
亚军方案使用 encoder-decoder 结构:
- Encoder 把多 MLP 编码的 user、item、interaction 序列表示聚合起来;
- encoded context 进一步通过 graph neural network 在 user-item 交互图的邻域上做聚合([54]);
- Decoder 基于改进版 SASRec-style([25])Transformer,将 next item 表示为 "next embedding";Transformer 配 2 048 hidden size、8 层、48 heads;
- 为了从多模态 context 抓取语义信息,模型还用 SVD-based residual-quantized mean RQ-KMeans([35])构造离散语义 ID;
- 参考 PinRec [1] 做 behavior-conditioned next-item 生成;训练是两阶段:先 pretrain 到 exposure 数据再 finetune 到 click+conversion,loss 为 InfoNCE;推理阶段把 decoder 输出 embedding 过一步后处理过滤用户历史出现过的物品。
7.3 第三名¶
季军方案是decoder-only Transformer:
- 输入特征方面,把 sparse user/item 属性与丰富的时间信号(绝对时间戳、相对 gap 等)拼接;
- 跟随 PinRec [1] 的设计,引入 action-type conditional signaling,使模型可以在 "下一步行为是点击还是转化" 条件下预测 next item;
- 使用 AMP 混合精度 + static graph compilation 提升效率;
- 核心贡献是对 GR 做scaling law 系统性研究([26]),在固定算力/显存预算下实验(i)对比 loss 负样本数、(ii)模型容量(Transformer 深度与宽度)、(iii)item-ID embedding 维度三个轴上的 scaling 行为;
- 显著地,他们把每 batch 负样本数推至 380K,性能进一步提升;结论支持"生成式推荐下,性能往往更多由规模驱动,而非精细模型结构"。
7.4 Technical Innovation Award¶
获奖团队使用 decoder-only 生成式模型联合建模用户下一次感兴趣物品与用户对该物品的 action,以 semantic-ID 生成损失 + action prediction 损失的统一目标训练。该设计探索 generative retrieval 与 ranking 的一体化范式,架构集成多项最新工程组件:FlashAttention [6]、SwiGLU FFN [50]、RMSNorm、RoPE [50]、DeepSeek-V3 风格的 Mixture-of-Experts。
Semantic-ID 构造模块提出两个关键创新:
- 可解码辅助 transformer + InfoNCE loss,强制 item embedding 同时对齐协同信号和其语义 code,构造更鲁棒的 semantic ID;
- next code token:在出现 hash 冲突时,自动搜索尚未占用的相邻 code,避免 code 碰撞导致的信息损失。
工程/特征侧:模型不仅保留原始 sparse user/item 特征,还额外输入 multi-modal item embedding;通过对多个滑窗做 item 统计,引入连续特征表示不同时间尺度下的 item popularity;训练阶段用多种 precision training、split sparse/dense optimizer、grouped GEMM、KV cache 加速,效率和扩展性上都有实质收益。
八、结论¶
作者把本工作总结为两个核心贡献:
- 首次公开一对真正大规模、多模态、工业广告级的生成式推荐 benchmark —— TencentGR-1M 与 TencentGR-10M,分别面向 click 与 click+conversion 场景,配套特征 schema、评估协议、加权指标、候选集构造流程和 baseline Transformer 实现;
- 首次提供一个涵盖数千支队伍 方法多样的公开 leaderboard 视角,数据显示生成式架构可以在工业广告场景达到或超过传统判别式模型,且冠军级方案普遍共同特征为:在 dense Transformer 骨干上引入 behavior-conditional signaling、时间粒度特征、RQ-KMeans 风格 semantic ID、以及系统性的 scaling(负样本数、模型容量、embedding 维度)。
数据集已发布到 HuggingFace Hub,baseline 代码和文档在 GitHub 可用。作者期望 TencentGR 系列能推动 all-modality generative recommendation 在工业规模、转化导向评测、真实广告上下文三个方向上的后续研究。
九、与社区工作的连接(阅读随笔)¶
- PinRec [1] 是本届比赛前后 GR 社区最常被引用的 behavior-conditional 方案,Top 三的队伍都借鉴了其"按 action type 条件生成 next item"的设计;
- TIGER [46] / LETTER [52] / DAS [59] / MMQ [55] / OneRec [68] 被作者列为工业级 semantic-ID / GR 的代表工作,TencentGR 的数据构造和评估基本沿袭这条线;
- HSTU [67] 等大模型序列推荐工作提供了"scaling 决定 GR 性能"的经验,季军团队的 scaling law 研究是该思想在广告数据上的延伸验证;
- Deep Interest Network (DIN/DIEN) [70,71] 与 Deep FM/Wukong 等特征交互模型 [5,14,16,...] 被作为 discriminative rec 的对照参考;
- 多模态 encoder 侧,Conan-embedding-v1 [30]、gte-Qwen2-7B-instruct [31]、hunyuan_mm_7B [32]、QQMM-embed-v1 [57]、UniME-LLaVA-OneVision-7B [13] 代表了腾讯内部当前对 ad creative 抽表征的主流选择——文本侧偏向 instruction-tuned LLM embedding,图像侧偏向多模态 LLM 适配层。
从工业 benchmark 的角度看,TencentGR 填补的最大空白是把 conversion 事件同时作为序列内事件和预测目标纳入公开数据集,这在此前的 MIND、KuaiRand、Tenrec 等数据集中是缺失的——此前研究者只能在 CTR 框架内近似评估,无法真正衡量 GR 对高价值转化事件的排序能力。决赛里 $\alpha=2.5$ 的行为加权是作者对"生成式模型能否感知并显式优化转化"这一问题的一次直接问答。
十、个人评价¶
本文核心定位是 dataset & competition report,而非方法论论文。其精读价值主要在于:
- 明确了工业级 GR 数据集的"黄金范式"——all-modality 特征 + 候选集构造 + 加权多行为评估;
- 对参赛 Top 方案的技术摘要,可作为 2025 年工业 GR 技术栈快照:Conditional GR + RQ-KMeans + Scaling + 高效 negative sampling;
- Baseline 的公式化与实现方案非常完整,可以直接作为后续 all-modality GR 研究的起点。
主要局限:论文未公开 baseline / Top 方案的定量指标,仅给出定性描述;也未给出 TencentGR 数据上生成式 vs 判别式的系统对比。作为一篇"问题发布"型论文,可以接受,但如果希望把 TencentGR 纳入学术 benchmark 追踪,还需要等作者(或社区)补充 baseline 分数表。